Cette section décrit le statut de ce document au moment
de sa publication. D'autres documents peuvent venir le remplacer. Une
liste des publications actuelles du W3C et la dernière révision de ce
rapport technique peuvent être trouvées dans l'index des rapports techniques du
W3C à l'adresse http://www.w3.org/TR/.
Voici la recommandation du 15 décembre 2004 de
l'"architecture du World Wide Web, volume Un". Après la revue de ce
document par des membres du W3C, des développeurs de logiciels, par
d'autres groupes du W3C et d'autres tiers intéressés, le Directeur l'a
approuvé comme recommandation du W3C. C'est un document stable, qui peut
servir en tant que documentation de référence ou être cité dans un autre
document. Le rôle du W3C, en produisant la recommandation, consiste à
attirer l'attention sur la spécification et à en promouvoir le large
déploiement. Elle participe à améliorer le fonctionnement et
l'interopérabilité du Web.
Ce document a
été produit par le groupe d'architecture technique [ndt. Technical Architecture
Group ou TAG], qui, selon la charte, maintient
une liste de
discussions au sujet de l'architecture. La portée de ce document
couvre un sous-ensemble utile de ces points. Il n'est pas prévu de les
traiter tous. Le TAG prévoit d'aborder les questions en suspens (ainsi que
les futures) maintenant que ce premier volume est édité en tant que
recommandation W3C. Un historique complet des changements de ce document est
disponible. Veuillez envoyer vos commentaires sur ce document à la liste
public-webarch-comments@w3.org (archives publiques). Les discussions techniques du TAG
ont lieu sur la liste www-tag@w3.org (archives publiques).
Ce
document a été produit dans le cadre de la politique IPR du W3C du document de processus de juillet
2001. Le TAG maintient une liste publique de révélations de brevet concernant ce
document ; cette page inclut également des instructions pour révéler
un brevet. Quiconque aurait connaissance de l'existence d'un brevet
susceptible de contenir une (ou plusieurs) revendication essentielle
concernant cette spécification devrait divulguer cette information,
conformément au chapitre 6 de la politique de brevetabilité du
W3C.
Le World Wide
Web (WWW ou plus simplement le
Web) est
un espace d'informations composé d'éléments caractérisés par identifiants
globaux, nommés des identifiants de ressource uniforme [ndt. Uniform
Resource Identifier](URI).
Les exemples, à l'image du scénario de voyage suivant, sont utilisés
tout au long de ce document pour illustrer le comportement typique d'agents Web
(personne ou logiciel agissant sur cet espace d'informations). Un agent
utilisateur représente un utilisateur. Le terme agent logiciel
comprend les serveurs, les proxies, les robots de recherche, les
navigateurs et les lecteurs multimédia.
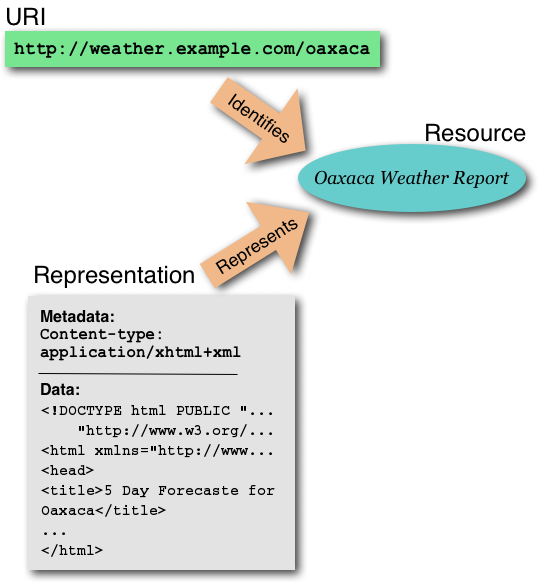
Scénario
Alors qu'elle organise un
voyage à Mexico, Nadia lit “les informations sur le temps à Oaxaca:
'http://weather.example.com/oaxaca'” dans son superbe magazine de voyage.
Nadia est suffisamment expérimentée quant à l'utilisation du web pour
reconnaître que "http://weather.example.com/oaxaca" est un URI et qu'elle
obtiendra certainement l'information appropriée via son navigateur Web.
Lorsqu'elle saisit l'URI dans son navigateur :
- Le navigateur reconnaît que l'information saisie par Nadia est un
URI.
- Le navigateur exécute une action d'obtention de l'information. Il
se base sur la configuration du comportement à adopter face aux
ressources identifiées par le schéma d'URI "http".
- L'autorité responsable de "weather.example.com" fournit
l'information en réponse à cette demande.
- Le navigateur interprète la réponse, identifiée comme étant du
XHTML par le serveur et effectue des actions additionnelles de
récupération pour les graphiques intégrés ainsi que pour tout autre
contenu nécessaire.
- Le navigateur affiche l'information recherchée, qui inclut des
liens hypertextes vers d'autres informations. Nadia peut alors suivre
ces liens pour rechercher une information complémentaire.
Ce scénario illustre
les trois bases architecturales du web qui sont abordées dans ce document
:
Identification (§2).Les URI sont utilisés pour
identifier des ressources. Dans ce scénario relatif au voyage, la
ressource est un bulletin météo à Oaxaca mis à jour périodiquement.
L'URI est “http://weather.example.com/oaxaca”.
Interaction (§3). Les agents web communiquent en
s'appuyant sur des protocoles normalisés qui permettent des
interactions grâce à l'échange de messages conformes à une syntaxe et
une sémantique définies. En saisissant un URI dans un dialogue de
récupération ou en choisissant un lien hypertexte, Nadia indique à son
navigateur d'effectuer une action pour obtenir la ressource identifiée
par l'URI. Dans cet exemple, le navigateur envoie une requête HTTP GET
(qui fait partie du protocole HTTP) au serveur situé à l'adresse
"weather.example.com", via le port TCP/IP 80. Le serveur retourne
alors un message contenant ce qu'il détermine être une représentation
de la ressource au moment de sa génération. Notez que cet exemple est
spécifique à la navigation dans des informations hypertextes —
d'autres genres d'interaction sont possibles, que ce soit par
l'intermédiaire de navigateurs ou d'autres types d'agent Web. Notre
exemple sert à illustrer une interaction classique et non à définir la
gamme des interactions possibles, ni à restreindre l'étendu des façons
d'utiliser le Web qu'ont les agents.
Formats (§4). La plupart des protocoles utilisés pour
la récupération et/ou la soumission de représentation se servent d'une
séquence d'un ou plusieurs messages. Pris ensemble, ils forment un
certain volume de données et de métadonnées pour la représentation,
qui est utilisé pour son transfert entre les agents. Le choix du
protocole d'interaction induit des limites sur les formats des données
et des métadonnées de la représentation qui peut être transmise. HTTP,
par exemple, transmet typiquement un flux simple d'octets plus des
métadonnées. Il emploie l'information "Content-Type" et les champs
d'en-tête "Content-Encoding" pour l'identification à posteriori du
format de la représentation. Dans ce scénario, la représentation est
transférée en XHTML, comme l'indique le champ d'en-tête HTTP
"Content-Type". Ce dernier contient, en effet, le type de média
Internet "application/xhtml+xml". Il indique que les données de la
représentation peuvent être traitées selon les spécifications de
XHTML.
Le navigateur de Nadia est
configuré et programmé pour interpréter la réception d'une
représentation ayant le type "application/xhtml+xml" comme étant une
instruction de formatage du contenu de cette représentation selon le
modèle de rendu XHTML. Il en va de même pour toutes les interactions
complémentaires (telles que les requêtes vers des feuilles externes ou
encore des images intégrées) réclamées par la représentation. Dans ce
scénario, les données de la représentation XHTML reçues, suite à la
demande initiale, indiquent par ailleurs au navigateur de Nadia de
récupérer et d'afficher les cartes météo incluses. Chacune est
identifiée par un URI et cause, de ce fait, une action supplémentaire
de récupération. Elle engendre d'autres représentations qui sont
traitées par le navigateur selon leurs propres formats de données (par
exemple, "application/svg+xml" indique le format de données de SVG).
Ce processus continue jusqu'à ce que tous les formats de données aient
été rendus. Le résultat de tous ces traitements, une fois que le
navigateur a atteint un état stable répondant à l'action initiale
demandée par Nadia, est généralement désigné par le terme de "Page
Web".
La figure suivante montre les
relations entre un identifiant, une ressource et une représentation.
Dans la suite de ce document, nous soulignerons les points importants
d'architecture ayant un rapport avec les identifiants Web, les protocoles
et les formats. Nous discuterons également des principes généraux d'architecture (§5) majeurs et comment
ils s'appliquent au Web.
Ce document décrit les propriétés que nous désirons pour le
web et les choix de conception faits pour les mettre en oeuvre. Il
favorise la réutilisation de standards existants lorsqu'ils sont
appropriés et donne des conseils sur la façon d'innover en étant en
conformité avec l'architecture du Web.
Les termes DOIT (DOIVENT), NE DOIT (DOIVENT) PAS, DEVRA
(DEVRONT), NE DEVRA (DEVRONT) PAS et PEUT (PEUVENT) sont utilisés dans les
principes, contraintes et bonnes pratiques. Ils sont décrits dans le
document [RFC2119].
Ce document n'inclut pas de dispositions de conformité pour
les raisons suivantes :
- La conformité logicielle se doit d'être si diverse qu'il ne semble
pas utile de pouvoir se référer à la classe de conformité des agents
logiciels.
- Certaines notes de bonnes pratiques concernent les personnes. Les
spécifications, quant à elles, définissent généralement la conformité
pour le logiciel et non pour les personnes.
- Nous ne croyons pas que l'ajout d'une section ayant pour objet la
conformité est susceptible d'augmenter l'utilité du document.
Le but de ce document est d'informer à propos des
discussions liées à l'architecture du Web. Le public visé par ce document
inclut :
- Les participants aux activités du W3C,
- D'autres groupes et personnes concevant des technologies devant
être intégrées au Web,
- Les personnes mettant en oeuvre les spécifications du W3C,
- Les auteurs et éditeurs de contenu Web.
Note: Ce document ne fait
aucune distinction formelle entre les termes "langage" et "format". Le
contexte détermine l'utilisation de chacun. L'expression "concepteur de
spécification" englobe les notions de conception de langage, de format et
de protocole.
Ce document présente
l'architecture générale du Web. D'autres groupes à l'intérieur et à
l'extérieur du W3C se concentrent également sur des aspects spécifiques de
l'architecture du Web, comme l'accessibilité, l'assurance qualité,
l'internationalisation, l'indépendance des dispositifs et les services
Web. La section concernant les spécifications liées à l'architecture (§7.1) fait
référence à ces spécifications.
Ce
document essaie d'atteindre un équilibre entre brièveté et précision tout
en illustrant par des exemples. Les conclusions du TAG
sont des documents d'information qui complètent le présent document en
fournissant plus de détails sur des points précis. Ce document inclut
quelques extraits de ces conclusions. Ces documents complémentaires
évoluant indépendamment, celui-ci inclut des références aux conclusions
approuvées par le TAG. Pour les autres discussions du TAG non approuvés
mais abordés ici, les références sont incluses dans la liste des
publications du TAG.
Beaucoup
d'exemples dans ce document, impliquant la participation d'une personne,
font l'hypothèse d'un modèle familier d'interaction avec le Web (illustré
au début de l'introduction) dans lequel une personne suit un lien par
l'intermédiaire d'un agent utilisateur, celui-ci récupère et présente les
données, puis l'utilisateur suit un autre lien, etc... Ce document
n'aborde aucun autre modèle d'interaction tel que la navigation avec la
voix (voir, par exemple, [VOICEXML2]). Le choix du modèle d'interaction peut avoir
un impact sur le comportement attendu d'un agent. Par exemple, lorsqu'un
agent utilisateur graphique, s'exécutant sur un ordinateur portable ou sur
un dispositif mobile, rencontre une erreur, il peut la rapporter
directement à l'utilisateur par des manifestations visuelles et sonores et
lui présenter des options pour la résoudre. D'autre part, lorsque
quelqu'un navigue sur le web via la voix et ne dispose que d'un retour
sonore, l'arrêt du dialogue pour attendre une information provenant de
l'utilisateur peut réduire sa facilité d'utilisation. Il est en effet
vraiment facile de "perdre le fil" en navigant uniquement avec une sortie
audio. Ce document ne traite pas de la façon dont les principes, les
contraintes et les bonnes pratiques identifiés ici s'appliquent dans tous
les contextes d'interaction.
Les points importants dans ce document sont classés par
catégorie comme suit :
- Principe
- Un principe architectural est une règle fondamentale qui
s'applique à un grand nombre de situations et de variables. Parmi ces
principes architecturaux se trouvent la "séparation des problèmes",
l'"interface générique", la "syntaxe auto-descriptive", une
"sémantique évidente", l'"effet de réseau" (la loi de Metcalfe) et la
loi d'Amdahl : "la vitesse d'un système est limitée par son composant
le plus lent".
- Contrainte
- Dans la conception du Web, certains choix, comme les noms des
éléments
p et li en HTML, le choix du
caractère deux points (:) dans les URI ou encore le regroupement des
bits en grappe de huit (octets) sont arbitraires. Si
paragraph avait été choisi à la place de p
ou l'astérisque (*) au lieu des deux points, le résultat à grande
échelle aurait été, très probablement, identique. Ce document se
concentre sur des choix de conception plus fondamentaux : les choix de
conception qui mènent aux contraintes, c'est-à-dire des restrictions
dans le comportement ou l'interaction dans le système. Ces contraintes
peuvent être imposées pour des raisons techniques, politiques ou
autres afin de réaliser des propriétés souhaitées dans le système,
comme l'accessibilité, la portée globale, la relative facilité
d'évolution, l'efficacité et l'extensibilité dynamique.
- Bonne
pratique
- Les bonnes pratiques, énoncées par des développeurs de logiciel,
les auteurs, les responsables de site, les utilisateurs et les
concepteurs de spécification, augmentent la valeur du Web.
Pour sa
communication interne, une communauté s'accorde (jusqu'à un degré
raisonnable) sur un ensemble de termes et sur leur signification. Un des
buts du Web, depuis sa genèse, a été d'établir une communauté globale dans
laquelle n'importe quelle partie peut partager une information avec
n'importe quelle autre partie. À dessein d'y parvenir, le web se sert d'un
système simple et global d'identification : l'URI. Les URI sont une pierre
angulaire de l'architecture du Web, fournissant une identification commune
à travers le Web. La portée globale des URI favorise les "effets de
réseau" à grande échelle : la valeur d'un identifiant augmente à mesure
qu'il est utilisé de façon consistante (par exemple, plus il est employé
dans les liens
hypertextes (§4.4)).
Principe: Identifiants globaux
Le nommage global conduit
aux effets de réseau global.
Ce
principe date au moins du temps où Douglas Engelbart effectuait un travail
séminal sur les systèmes hypertextes ouverts ; voir la section chaque objet accessible dans le document [Eng90].
Le choix de la syntaxe pour
les identifiants globaux est quelque peu arbitraire ; l'important reste
leur portée globale. L'identifiant de
ressource uniforme, [URI], a été
déployé avec succès depuis la création du Web. Il y a des avantages
substantiels à participer au réseau existant d'URI, comme l'établissement
de liens, de signets, de mise en mémoire cache et l'indexation par des
moteurs de recherche. Par ailleurs, créer un nouveau système
d'identification qui possède les mêmes propriétés que les URI, induit un
coût non négligeable.
Bonne pratique : Identifier à l'aide
d'URI
Pour
tirer parti du web global et en augmenter la valeur, les agents devraient
fournir des URI comme identifiants de ressources.
Une ressource devrait avoir un URI associé à
partir du moment où une tierce partie peut vouloir créer un lien
hypertexte vers elle, faire ou réfuter des affirmations à son sujet,
rechercher ou mettre en mémoire cache une représentation la concernant,
l'inclure en partie ou dans son ensemble en la référençant dans une autre
représentation, l'annoter ou encore effectuer d'autres opérations. Les
développeurs de logiciels devraient attendre une certaine utilité du
partage d'URI à travers des applications, même si elle n'est pas évidente
de prime abord. Les conclusions du TAG sur "les
URI, la possibilité d'adressage et l'utilisation du HTTP GET et POST
[URIs, Addressability, and the use of HTTP GET and POST]"
montrent les avantages complémentaires et la possibilité d'adressage par
les URI.
Note: Les
schémas d'URI (tels que les spécifications du schéma "ftp") emploient le
terme "désigner" alors que ce document utilise "identifier".
Par conception, un URI identifie une ressource. Nous ne limitons pas la
portée de ce qui pourrait être une ressource. Le terme "ressource" est
employé dans un sens général pour qualifier tout ce qui pourrait être
identifié par un URI. Il est courant, sur le web hypertexte, de décrire
des pages Web, des images, des catalogues de produits, etc... comme étant
des “ressources”. Les caractéristiques essentielles qui différencient ces
ressources peuvent être empaquetées dans un message. Nous identifions cet
ensemble par l'expression “ressources de
l'information”.
Ce document
est un exemple de ressources d'information. Il se compose de mots, de
symboles de ponctuation, de graphiques et d'autres objets qui peuvent être
encodés en une séquence de bits, avec un degré variable de fidélité. En
principe, tout ce qui compose l'essentiel de l'information de ce document
peut transféré dans un message, dont la valeur ajoutée est une représentation de ce
document.
Cependant, notre utilisation
du terme ressource est intentionnellement plus large. D'autres choses,
comme des voitures et des chiens (et, si vous avez imprimé ce document sur
des feuilles de papier, l'objet que vous tenez dans vos mains), sont
également des ressources. Mais il ne s'agit pas de ressources
d'information, car leur essence n'est pas de l'information. Même s'il est
possible de décrire un grand nombre de choses au sujet d'une voiture ou
d'un chien dans une séquence de bits, la somme de ces choses sera toujours
une approximation du caractère essentiel de la ressource.
Nous définissons le terme “ressource de
l'information” car nous observons qu'il est utile lors des discussions à
propos de la technologie web et peut l'être lors de l'élaboration de
spécifications pour des équipements construits pour un usage sur le
Web.
Contrainte : Les URI identifient une ressource
simple
Assignez des URI distincts à des ressources distinctes.
Puisque la portée d'un URI est globale, la
ressource identifiée par un URI ne dépend pas du contexte dans lequel elle
apparaît (voir également la section au sujet de l'identification indirecte
(§2.2.3)).
Un [URI] est un accord sur la façon dont la communauté
Internet assigne des noms et les associe aux ressources qu'ils
identifient. Les URI sont divisés en schémas (§2.4) qui définissent, par l'intermédiaire de
leur spécification, le mécanisme par lequel des identifiants spécifiques
au schéma sont associés aux ressources. Par exemple, le schéma d'URI
"http" ([RFC2616]) utilise des
serveurs DNS et HTTP, basés sur TCP, afin d'attribuer et de résoudre un
identifiant. Par conséquent, les identifiants tels que
"http://example.com/somepath#someFrag" signifie souvent, au vu de
l'expérience de la communauté, l'exécution d'une requête HTTP GET à partir
de l'identifiant et si la réponse est correcte, l'interprétation de la
réponse comme étant une représentation de la ressource identifiée. (voir
également les identifiants de fragment
(§2.6)). Naturellement, une action de récupération comme un GET n'est
pas la seule manière d'obtenir des informations au sujet d'une ressource.
On pourrait également éditer un document qui prétend définir la
signification d'un URI particulier. Ces autres sources d'information
peuvent suggérer des significations pour de tels identifiants, cependant
l'observation de ces suggestions relève d'une politique locale.
De la même façon que l'on pourrait souhaiter se
référer à une personne par l'intermédiaire de différents noms (par son nom
et son prénom, seulement par prénom, par un surnom lié au sport, par un
surnom romantique et ainsi de suite), l'architecture du web permet
d'associer plus d'un URI à une ressource. Les URI qui identifient la même
ressource sont nommés des alias d'URI. La section les
concernant (§2.3.1) revient sur
certains coûts potentiels relatifs à la création d'URI multiples pour la
même ressource.
Plusieurs sections de ce
document abordent la relation entre les URI et les ressources, comme :
Par conception, un URI identifie une ressource.
L'utilisation d'un même URI pour identifier directement différentes
ressources produit une collision d'URI. Une collision
induit souvent un coût dans la communication relatif à l'effort exigé par
la levée des ambiguïtés.
Supposons, par
exemple, qu'une organisation se sert d'un URI pour se référer au film
"The Sting" et qu'une autre organisation emploie le même URI
pour se rapporter à un forum de discussion au sujet de ce film. Pour un
tiers, familier des deux organismes, cette collision crée une confusion au
sujet de ce que l'URI identifie, diminuant ainsi la valeur de cet URI. Par
exemple, si quelqu'un voulait parler de la date de création de la
ressource identifiée par l'URI, il ne serait pas clair de savoir si elle
signifie "quand le film a été créé" ou "quand le forum de discussion au
sujet du film a été créé."
Des solutions
sociales et techniques ont été conçues pour aider à éviter la collision
d'URI. Cependant, le succès ou l'échec de ces différentes approches dépend
de l'importance du consensus qui existe dans la communauté Internet à
propos du respect des spécifications les définissant.
La section sur l'attribution d'URI (§2.2.2) examine des approches pour
établir la source d'informations appropriée permettant de définir quelle
ressource est identifiée par un URI.
Les
URI sont parfois utilisés pour des identifications indirectes (§2.2.3). Cela ne conduit pas
nécessairement à des collisions.
L'attribution d'URI est le processus consistant à associer
un URI à une ressource. L'attribution peut tout aussi bien se faire par
les propriétaires de ressource ou par d'autres parties. L'important est
d'éviter les collisions d'URI
(§2.2.1).
La propriété d'URI est une relation
entre un URI et une entité sociale, telle qu'une personne, une
organisation ou une spécification. La propriété d'URI procure certains
droits à l'entité sociale concernée, comme :
- la possibilité de transmettre, à un tiers, la propriété de
certaines ou de toutes les URI possédés (délégation) et
- d'associer une ressource à un URI possédé (attribution
d'URI).
Par convention sociale, la propriété
d'URI est déléguée depuis le référentiel des schémas d'URI de l'IANA [IANASchemes], lui-même une entité
sociale, aux spécifications de schémas d'URI enregistrés auprès de l'IANA.
Certaines spécifications de schémas d'URI délèguent la propriété à des
référentiels subordonnés ou à d'autres propriétaires explicitement nommés,
qui peuvent, de la même façon déléguer cette propriété. Dans le cas d'une
spécification, la propriété appartient finalement à la communauté qui
maintient cette spécification.
L'approche adoptée pour le schéma d'URI "http", par
exemple, suit le modèle selon lequel la communauté Internet délègue la
responsabilité, par l'intermédiaire du référentiel de schémas d'URI de
l'IANA et du DNS, au moyen d'un ensemble d'URI ayant un préfixe commun, à
un propriétaire particulier. La forte confiance du web dans le répertoire
central DNS est une des conséquences de cette approche. Une approche
différente est adoptée par le schéma de la syntaxe URN [RFC2141] qui délègue la propriété des différentes parties
de l'espace d'URN aux spécifications de l'espace de noms URN, qui sont
elles-mêmes enregistrées dans un référentiel d'identifiants d'espace de
noms, maintenu par l'IANA.
Les
propriétaires d'URI sont chargés d'éviter l'attribution d'URI équivalents
à des ressources multiples. Ainsi, si des spécifications de schéma d'URI
prévoient la délégation d'un URI ou d'ensembles organisés d'URI, il est
nécessaire de prendre les mesures visant à s'assurer que la propriété
réside finalement entre les mains d'une entité sociale unique. Permettre
des propriétaires multiples augmente la probabilité de collisions
d'URI.
Les propriétaires d'URI peuvent
organiser ou déployer une infrastructure afin de s'assurer que les
représentations des ressources associées sont disponibles et, le cas
échéant, que l'interaction avec la ressource est possible par le biais
d'échange de représentations. La gestion [responsable] des
représentations (§3.5) par les propriétaires d'URI est source
d'attentes sociales. Les autres implications sociales concernant la
propriété d'URI ne sont pas abordées ici.
Voir les discussions du TAG siteData-36, concernant l'expropriation d'autorité de
nommage.
Certains
schémas utilisent d'autres techniques que la propriété déléguée afin
d'éviter les collisions. Par exemple, la spécification pour le schéma
d'URL de données (sic) [RFC2397]
indique qu'une ressource identifiée par un schéma d'URI de données ne
possède qu'une seule représentation possible. Les données de la
représentation composent l'URI qui identifie cette ressource. Ainsi, la
spécification elle-même détermine comment les URI de données sont
attribués ; aucune délégation n'est possible.
D'autres schémas (comme "news:comp.text.xml") se basent sur
un processus social.
Énoncer que l'URI "mailto:nadia@example.com" identifie à la
fois une boîte aux lettres Internet et Nadia, introduit une collision
d'URI. Par contre, l'URI peut servir à identifier indirectement Nadia. Et,
c'est de cette façon que les identifiants sont généralement employés.
En écoutant les actualités, il est possible
d'entendre un reportage sur la Grande-Bretagne commençant ainsi :
"Aujourd'hui, le 10 Downing Street a annoncé une série de nouvelles
mesures économiques". En général, le "10 Downing Street" identifie la
résidence officielle du premier ministre anglais. Dans ce contexte, le
journaliste emploie cette formule (comme la rhétorique le permet) pour
identifier indirectement le gouvernement britannique. De la même façon,
les URI identifient des ressources, mais elles peuvent également servir,
dans bien des cas, à désigner indirectement d'autres ressources. Les
politiques d'attribution adoptées de façon globale font de certains URI
des identifiants généraux. La politique locale, quant à elle, établit ce
qu'ils identifient de façon indirecte.
Supposons que nadia@example.com soit l'adresse
de courrier électronique de Nadia. Les organisateurs d'une conférence à
laquelle elle assiste pourraient employer "mailto:nadia@example.com" pour
se référer indirectement à elle (par exemple, en se servant de l'URI comme
clef dans leur base de données des participants à la conférence). Cela ne
constitue pas un cas de collision d'URI.
Les URI, qui sont identiques au caractère
près, se réfèrent à la même ressource. L'architecture du web permet
d'associer plusieurs URI à une ressource donnée. Ainsi deux URI non
identiques (caractère pour caractère) peuvent se rapporter à une même
ressource. Des URI différents ne se rapportent donc pas nécessairement à
des ressources différentes. Cela induit cependant un coût informatique
plus élevé pour déterminer que des URI différents se rapportent à la même
ressource.
Pour réduire le risque de
cas faussement négatif (c'est-à-dire, une conclusion erronée sur le fait
que deux URI ne se rapportent pas à la même ressource) ou de cas
faussement positif (c'est-à-dire, une conclusion inexacte sur le postulat
que deux URI se rapportent effectivement à la même ressource), certaines
spécifications décrivent des tests d'équivalence complémentaires à la
comparaison caractère par caractère. Les agents qui tirent des conclusions
en se basant sur des comparaisons non approuvées par les spécifications
concernées engagent leur responsabilité pour tout problème potentiel
résultant ; pour plus d'informations sur le comportement responsable à
adopter face à des conclusions non autorisées, voir la section sur la gestion des erreurs
(§5.3). La section 6 des [URI] fournit
plus d'informations sur la comparaison d'URI et sur la réduction du risque
de jugement faussement négatif et positif.
Voir également l'affirmation que deux URI identifient la même ressource
(§2.7.2).
Bien que les alias d'URI présentent des avantages (comme la
flexibilité en matière de nommage), il est bon de considérer également
leurs coûts. Les alias d'URI sont nocifs quand ils divisent un ensemble
(le Web) composé de ressources liées entre elles. Un corollaire du
principe de Metcalfe (l'"effet de réseau") veut que la valeur d'une
ressource donnée peut être mesurée par le nombre et la valeur des autres
ressources dans son voisinage réseau, c'est-à-dire, les ressources qui
font un lien vers elle.
Les alias posent
un problème. Si une même ressource est désignée, grâce à un URI donné, par
la moitié d'un ensemble et qu'elle est également désignée à l'aide d'un
deuxième URI par la seconde moitié de cet ensemble, une division se crée.
Non seulement la ressource perd de sa valeur en raison de cette fracture,
mais c'est l'ensemble des ressources qui se dévalue en raison de l'absence
des relations qui auraient dû exister entre les ressources faisant des
références.
Bonne pratique : Éviter les alias
d'URI
Un
propriétaire d'URI NE DEVRAIT PAS associer arbitrairement différents URI à
la même ressource.
Les
consommateurs d'URI ont également un rôle à jouer en s'assurant de la
cohérence de l'URI. Par exemple, lors de la transcription d'un URI, les
agents ne devraient pas encoder, de façon gratuite, les caractères avec
des pourcents. Le terme "caractère" se rapporte à des caractères d'URI
(voir la définition dans la section 2 des [URI]). L'encodage avec des pourcents est discuté dans la
section 2.1 de cette spécification.
Bonne pratique : Usage consistant des
URI
Un
agent qui reçoit un URI DEVRAIT se référer à la ressource associée en
utilisant le même URI, caractère-par-caractère.
Lorsqu'un URI devient monnaie courante, le propriétaire de l'URI devrait
utiliser des techniques se basant sur le protocole, telles que la
redirection côté serveur, pour relier les deux ressources. Le support, par
son propriétaire, de la redirection d'un alias d'URI vers l'URI "officiel"
bénéficie à toute la communauté. Pour plus d'informations sur la
redirection, voir la section 10.3, "Redirection", dans la [RFC2616]. Voir également [CHIPS] pour une discussion sur certaines
des meilleures pratiques pour les administrateurs de serveur.
Le phénomène d'alias
d'URI ne se produit que lorsque plus d'un URI est utilisé pour identifier
la même ressource. Le fait que différentes ressources possèdent parfois la
même représentation ne fait pas pour autant de ces URI des alias.
Scénario
Sur son site Web, Dirk voudrait ajouter un lien au site
donnant la météo à Oaxaca. Il se sert alors de l'URI
http://weather.example.com/oaxaca et étiquette son lien "temps à Oaxaca,
le 1 août 2004". Nadia précise à Dirk qu'il se trompe vis-à-vis
de la pertinence de l'URI employé. La politique de ce site définit que
l'URI en question identifie le temps courant à Oaxaca (quel que soit le
jour) et non le temps du 1 août. Naturellement, le premier jour d'août
2004, le lien de Dirk sera correct. Mais le reste du temps, il induira en
erreur les visiteurs de son site Web. Nadia signale à Dirk que ce site
météo fournit un URI différent, disponible de manière permanente et
assigné à une ressource décrivant le temps du 1 août 2004.
Dans cette histoire, il y a deux
ressources : "le temps courant à Oaxaca" et "le temps à Oaxaca le
1 août 2004". Le site donnant la météo à Oaxaca assigne deux URI
à ces deux ressources différentes. Le 1 août 2004, les
représentations pour ces ressources sont identiques. Le fait que le
déréférencement de deux URI différents produit des représentations
identiques ne permet pas de conclure que les deux URI sont des alias.
Dans l'URI "http://weather.example.com/", le terme "http"
qui précède les deux points (":") nomme un schéma d'URI. Chacun de ces
schémas d'URI possède une spécification particulière qui détaille comment
les identifiants de ce schéma sont alloués et sont associés à une
ressource. La syntaxe d'URI est ainsi un système d'appellation fédéré et
extensible dans lequel la spécification de chaque schéma peut limiter la
syntaxe et la sémantique des identifiants du schéma.
Exemples d'URI provenant de divers schémas :
- mailto:joe@example.org
- ftp://example.org/aDirectory/aFile
- news:comp.infosystems.www
- tel:+1-816-555-1212
- ldap://ldap.example.org/c=GB?objectClass?one
- urn:oasis:names:tc:entity:xmlns:xml:catalog
Même si l'architecture du web permet
la définition de nouveaux schémas, une telle introduction est coûteuse. De
nombreux aspects du traitement d'URI sont dépendants d'un schéma
particulier. Par ailleurs, un grand nombre de logiciels déployés traite
déjà les schémas d'URI bien connus. L'introduction d'un nouveau schéma
d'URI exige le développement et le déploiement non seulement de logiciels
clients pouvant manipuler le schéma, mais également d'agents auxiliaires
tels que des passerelles, des proxies et des systèmes de mémoire cache.
Voir la [RFC2718] pour d'autres
considérations et les coûts liés à la conception de schéma d'URI.
En raison de ces coûts, si un schéma d'URI
existant satisfait les besoins d'une application, les concepteurs
devraient l'employer plutôt que d'en inventer un.
Bonne pratique : Réutiliser les schémas
d'URI
Une
spécification DEVRAIT réutiliser un schéma d'URI existant (plutôt que d'en
créer un nouveau) lorsqu'il fournit les propriétés désirées pour les
identifiants et leurs relations aux ressources.
Considérons notre scénario de voyage : Est-ce que l'agent fournissant des
informations au sujet du temps à Oaxaca devrait enregistrer un nouveau
schéma d'URI "weather" pour identifier des ressources liées au temps ?
Elles pourraient alors servir à des URI comme
"weather://travel.example.com/oaxaca". Quand un agent logiciel déréférence
ce type d'URI, si l'action réelle est un HTTP GET, servant à obtenir une
représentation de la ressource, alors un URI "http" devrait suffire.
L'IANA
(Internet Assigned Numbers Authority) maintient un référentiel [IANASchemes] des correspondances
entre les noms de schéma d'URI et leur spécification. Par exemple, ce
référentiel indique que le schéma "http" est défini par la [RFC2616]. Le processus pour enregistrer
un nouveau schéma d'URI est, quant à lui, défini par la [RFC2717].
Les schémas d'URI non enregistrés NE DEVRAIENT PAS être
utilisés pour un certain nombre de raisons :
- En général, il n'y a pas de moyen reconnu pour accéder à la
spécification du schéma,
- Le schéma peut être utilisé par d'autres dans des buts
différents,
- Il ne faut pas s'attendre à ce qu'un logiciel généraliste puisse
faire quoi que ce soit d'utile avec ce type de schéma d'URI, mise à
part la comparaison d'URI.
Une motivation malencontreuse qui
pousse à enregistrer un nouveau schéma d'URI consiste à permettre à un
agent logiciel de lancer une application particulière lorsqu'il obtient
une représentation. Il est possible d'obtenir le même résultat, mais à
moindre coût, en s'appuyant plutôt sur le type de la représentation,
permettant alors l'utilisation de protocoles et de mises en oeuvre de
transfert existants.
Même si un format
inconnu empêche un agent de traiter des données liées à une
représentation, il peut néanmoins la récupérer. Les données peuvent
contenir des informations suffisantes pour permettre à un utilisateur ou à
un agent utilisateur d'en faire une certaine utilisation. A contrario
lorsqu'un agent ne sait pas traiter un nouveau schéma d'URI, il ne peut
pas en obtenir de représentation.
Lors
de la conception d'un nouveau format de données, le mécanisme de choix
pour favoriser son déploiement sur le web est l'utilisation du type de
média Internet (voir les types
de représentation et les types de média Internet (§3.2)). Les types de
média fournissent également des moyens pour construire de nouvelles
applications d'information, comme décrit dans les futures directions pour les
formats de données (§4.6).
Il est tentant de deviner la
nature d'une ressource en examinant un URI qui l'identifie. Cependant, le
web est construit de telle sorte que les agents communiquent l'état des
ressources d'information à l'aide de représentations et non via des identifiants. En général,
il n'est pas possible de déterminer le type de la représentation d'une
ressource en examinant un URI de cette ressource. Par exemple, le ".html"
terminant "http://example.com/page.html" ne fournit aucune garantie sur le
fait que la représentation de la ressource identifiée sera servie avec le
type de média Internet "text/html". L'éditeur est libre d'assigner des
identifiants et de définir comment ils sont servis. Le protocole HTTP ne
contraint pas le type de média Internet à se baser sur le composant chemin
de l'URI. Le propriétaire de l'URI est libre de configurer le serveur pour
renvoyer une représentation en utilisant par exemple PNG ou tout autre
format de données.
L'état d'une
ressource peut évoluer dans le temps. Exiger d'un propriétaire d'URI de
publier un nouvel URI pour chaque changement d'état de la ressource
conduirait à un nombre significatif de références cassées. Pour apporter
plus de robustesse, l'architecture du web met en avant l'indépendance
entre un identifiant et l'état de la ressource identifiée.
Bonne pratique : Opacité d'URI
Les agents, utilisant des
URI, NE DEVRAIENT PAS essayer de déduire des propriétés à partir de la
ressource référencée.
En
pratique, un nombre restreint de déductions, explicitement autorisées par
les spécifications sous-jacentes, peuvent être faites. Certaines de ces
déductions sont abordées dans la section qui détaille l'obtention d'une
représentation (§3.1.1).
L'URI
d'exemple utilisé dans le scénario de
voyage ("http://weather.example.com/oaxaca") suggère à un lecteur
(humain) que la ressource identifiée a un rapport avec le temps à Oaxaca.
Un site indiquant le temps à Oaxaca pourrait tout aussi bien être
identifié par l'URI "http://vjc.example.com/315". Par ailleurs, l'URI
"http://weather.example.com/vancouver" pourrait identifier la ressource
"mon album photo".
D'un autre côté,
l'URI "mailto:joe@example.com" indique que l'URI se réfère à une boîte aux
lettres. La spécification du schéma d'URI "mailto" autorise les agents à
déduire que les URI de cette forme identifient des boîtes aux lettres
Internet.
Certaines autorités
d'attribution d'URI documentent et éditent leur politique d'assignation
d'URI. Pour plus d'informations sur l'opacité d'URI, voir les discussions
du TAG metaDataInURI-31 et siteData-36.
Scénario
Lorsque Nadia lit le document XHTML qu'elle a reçu, comme
étant une représentation de la ressource identifiée par
"http://weather.example.com/oaxaca", elle constate que l'URI
"http://weather.example.com/oaxaca#weekend" se réfère à la partie de la
représentation qui donne des informations sur les perspectives du
week-end. Cet URI inclut l'identifiant de fragment "weekend" (la chaîne de
caractères après le "#").
Le composant identifiant de fragment d'un URI permet
l'identification indirecte d'une ressource secondaire en se
référant à une ressource primaire et à une information d'identification
additionnelle. La ressource secondaire peut être une certaine partie ou un
sous-ensemble de la ressource primaire, une certaine vue sur des
représentations de la ressource primaire ou une autre ressource définie ou
décrite par ces représentations. Les termes "ressource primaire" et
"ressource secondaire" sont définis dans la section 3.5 du document [URI].
Les
termes "primaire" et "secondaire" dans ce contexte ne limitent pas la
nature de la ressource (ce ne sont pas des classes). Dans ce contexte,
primaire et secondaire indiquent simplement qu'il existe une relation
entre les ressources qui forment un URI : l'URI avec un identifiant de
fragment. Toute ressource peut être identifiée comme étant une ressource
secondaire. Elle pourrait également être identifiée en utilisant un URI
sans identifiant de fragment. Une ressource peut être identifiée comme
ressource secondaire par l'intermédiaire d'URI multiples. Le but de ces
termes est de permettre de discuter de la relation entre de telles
ressources et non de se limiter à la nature d'une ressource.
L'interprétation des identifiants de fragment
est abordée dans la section concernant les types de représentation et sémantique de l'identifiant de
fragment (§3.2.1).
Voir la
discussion du TAG abstractComponentRefs-37, qui concerne l'utilisation des
identifiants de fragment avec des espaces de noms pour l'identification
des composants abstraits.
Il reste des questions en suspens concernant les
identifiants sur le Web.
L'intégration des
identifiants internationalisés (c'est-à-dire, composés de caractères
outrepassant ceux permis par les [URI])
dans l'architecture web est un sujet important et ouvert. Voir la
discussion du TAG, IRIEverywhere-27, abordant le travail mené à propos de
cette problématique.
Les technologies sémantiques naissantes, comme "le Langage
d'Ontologie Web (OWL)" [OWL10],
définissent des propriétés RDF, telles que sameAs pour
affirmer que deux URI identifient la même ressource ou
inverseFunctionalProperty pour le suggérer.
La
communication, entre des agents au travers d'un réseau, au sujet de
ressources implique des URI, des messages et des données. Les protocoles
du web (tels que HTTP, FTP, SOAP, NNTP et SMTP) sont basés sur l'échange
de messages. Un message peut inclure des données, mais
aussi des métadonnées (comme les en-têtes HTTP "Alternates" et "Vary"), au
sujet d'une ressource, des données du message et du message lui-même (à
l'image de l'en-tête HTTP "Transfer-encoding"). Un message peut même
inclure des métadonnées relatives aux métadonnées du message (pour la
vérification de l'intégrité du message, par exemple).
Scénario
Nadia suit un lien hypertexte, dont le nom est "image
satellite". Elle s'attend ainsi à obtenir une photo satellite de la région
d'Oaxaca. Le lien vers l'image satellite est un lien XHTML codé ainsi
<a href="http://example.com/satimage/oaxaca">image
satellite</a>. Le navigateur de Nadia analyse l'URI et
détermine que son schéma est
"http". La configuration du navigateur déduit la façon de localiser
l'information identifiée. Ce peut être par l'intermédiaire d'une zone de
cache, contenant des actions de récupération déjà effectuées, par le
contact d'un intermédiaire (tel qu'un serveur proxy) ou par accès direct
au serveur identifié par une partie de l'URI. Dans cet exemple, le
navigateur ouvre une connexion réseau sur le port 80 du serveur situé à
l'adresse "example.com". Puis, il envoie un message "GET", comme le
protocole HTTP le spécifie, pour demander une représentation de la
ressource.
Le serveur envoie alors un
message de réponse au navigateur, en conformité une nouvelle fois avec le
protocole HTTP. Le message se compose de plusieurs en-têtes et d'une image
JPEG. Le navigateur lit les en-têtes, déduit du champ "Content-Type" que
le type de média Internet de la représentation est "image/jpeg". Il lit
alors la séquence d'octets qui composent les données de la représentation
et affiche l'image.
Cette section décrit les principes et les contraintes
d'architecture concernant les interactions entre les agents. Il s'agit de
sujets comme les protocoles réseau et les modèles d'interaction, ainsi que
les interactions entre le web en tant que système et les personnes qui
s'en servent. Le fait que le web soit un système fortement réparti affecte
les contraintes et les suppositions liées à l'architecture au sujet des
interactions.
Les agents peuvent
utiliser un URI pour accéder à la ressource référencée. C'est le concept
de déréférencement
d'URI. L'accès peut prendre diverses formes, comme l'obtention
d'une représentation de la ressource (par exemple, en utilisant un GET ou
un HEAD HTTP), l'ajout ou la modification une représentation de la
ressource (par exemple, en utilisant un POST ou un PUT HTTP, qui dans
certains cas peut changer l'état réel de la ressource si les
représentations soumises sont interprétées comme étant des instructions
destinées à cet effet) et la suppression d'une partie ou de toutes les
représentations de la ressource (par exemple, via un DELETE HTTP, qui dans
certains cas peut avoir comme conséquence la suppression de la ressource
elle-même).
A partir d'un URI donné,
il peut y avoir plusieurs façons d'accéder à une ressource. Le contexte de
l'application détermine la méthode d'accès utilisée par un agent. Par
exemple, un navigateur peut se servir d'un GET HTTP pour obtenir une
représentation d'une ressource, tandis qu'un contrôleur de liens
hypertextes pourrait utiliser un HEAD HTTP pour le même URI, dans le
simple but de déterminer si une représentation est disponible. Certains
schémas d'URI ont des exigences à propos des méthodes d'accès disponibles,
d'autres n'en ont pas (tel que le schéma d'URN [RFC 2141]). La section 1.2.2 du document [URI] aborde, plus en détail, la séparation entre
identification et interaction. Pour plus d'informations sur les relations
entre les méthodes d'accès multiples et la possibilité d'adressage des
URI, reportez-vous aux conclusions du TAG "URI,
la possibilité d'adressage et l'utilisation du GET et du POST HTTP [URIs,
Addressability, and the use of HTTP GET and POST]".
Bien que de nombreux schémas d'URI (§2.4) soient baptisés du nom des
protocoles, l'utilisation d'un URI donné n'implique pas nécessairement
l'accès à la ressource par l'intermédiaire du protocole nommé. Même
lorsqu'un agent emploie un URI pour obtenir une représentation, cet accès
peut se faire par l'intermédiaire de passerelles, de proxies, de zones de
cache et de services de résolution de noms qui sont indépendants du
protocole lié au schéma en question.
Beaucoup de schémas d'URI définissent un protocole par
défaut pour tenter d'accéder à la ressource identifiée. Ce protocole
d'interaction sert souvent de base pour attribuer des identifiants
appartenant au schéma, comme les URI de "HTTP" sont définis en termes de
serveurs HTTP basés sur TCP. Cependant, cela n'implique pas que chaque
interaction avec de telles ressources est limitée au protocole
d'interaction par défaut. Par exemple, les systèmes de récupération
d'informations se servent souvent des proxies pour interagir avec une
multitude de schémas d'URI. En effet, l'utilisation de proxies HTTP permet
d'accéder à des ressources "ftp" et "wais". Ces proxies peuvent également
fournir des services étendus, à l'image des proxies d'annotation. Ceux-ci
combinent l'obtention classique d'information avec une récupération
complémentaire de métadonnées afin de fournir une vue parfaite et
multidimensionnelle des ressources qui utilisent les mêmes protocoles et
les mêmes agents utilisateurs que le web non annoté. De même, de futurs
protocoles pourront être définis et engloberont nos systèmes actuels,
utilisant des mécanismes d'interaction totalement différents, mais sans
pour autant changer les schémas existants des identifiants. Voir également
le principe des spécifications
orthogonales (§5.1).
Déréférencer un URI implique généralement une succession
d'étapes qui sont décrites dans de multiples spécifications et mises en
oeuvre par les agents. L'exemple suivant illustre la série de
spécifications qui régit le processus à suivre lorsqu'un agent utilisateur
doit suivre un lien hypertexte
(§4.4) faisant partie d'un document SVG. Dans cet exemple, l'URI est
"http://weather.example.com/oaxaca" et le contexte d'application demande à
l'agent utilisateur d'obtenir et d'afficher une représentation de la
ressource identifiée.
- L'URI faisant partie d'un lien hypertexte dans un document SVG, la
recommandation SVG 1.1 [SVG11] est
la première spécification appropriée. La section 17.1 de cette spécification importe la sémantique du
lien définie dans XLink 1.0 [XLink10] : "La ressource distante (la destination du
lien) est définie par un URI spécifié par l'attribut XLink
href sur l'élément 'a'". La spécification de
SVG va plus loin en déclarant que l'interprétation d'un élément
a implique d'obtenir une représentation d'une ressource,
identifiée par l'attribut href appartenant à l'espace de
noms XLink : "En activant ces liens (en cliquant avec la souris, par
une saisie clavier, une commande vocale, etc...), les utilisateurs
peuvent visiter ces ressources."
- La spécification XLink 1.0 [XLink10], qui définit l'attribut
href
dans la section 5.4, déclare que "La valeur de l'attribut href doit
être une référence d'URI, comme défini dans le document [IETF RFC
2396], ou encore doit aboutir à une référence d'URI après que la
procédure d'échappement [ndt. escaping procedure] ci-dessous a été
appliqué. La procédure s'applique lors du passage de la référence
d'URI à un résolveur d'URI."
- La spécification d'URI [URI]
annonce que "chaque URI commence par un nom de schéma qui se réfère à
une spécification pour assigner des identifiants suivant ce schéma".
Le nom de schéma d'URI, dans cet exemple, est "http".
- [IANASchemes] spécifie que
le schéma "http" est défini par la spécification HTTP/1.1 (RFC 2616
[RFC2616], section 3.2.2).
- Dans ce contexte SVG, l'agent construit une requête HTTP GET (en
se basant sur la section 9.3 de la [RFC2616]) pour obtenir la représentation.
- La section 6 de la [RFC2616]
définit comment le serveur construit le message de réponse
correspondant, y compris en ce qui concerne le champ
'Content-Type'.
- La section 1.4 de la [RFC2616]
stipule que la "communication HTTP a lieu habituellement au-dessus des
connexions TCP/IP". Cet exemple n'aborde ni cette étape du processus
ni d'autres étapes telles que la résolution du DNS
(Domain Name System).
- L'agent interprète la représentation retournée selon la
spécification en corrélation avec le format de données, correspondant
au type de média
Internet de la représentation (§3.2) (la valeur du champ HTTP
'Content-Type') du registre IANA approprié [MEDIATYPEREG].
Un certain nombre de facteurs,
décrits ci-dessous, influencent qu'elle est (sont) la(les)
représentation(s) obtenue(s) :
- Si le propriétaire de l'URI rend disponibles toutes les
représentations,
- Si l'agent, formulant la requête, possède les privilèges d'accès
pour ces représentations (voir la section sur les liens et contrôle d'accès (§3.5.2)),
- Si le propriétaire de l'URI a fourni plus d'une représentation
(dans différents formats tels que HTML, PNG ou RDF, dans différentes
langues comme l'anglais et l'espagnol, ou si elle est issue d'une
transformation dynamique selon les capacités matérielles ou
logicielles du destinataire), la représentation résultante peut
dépendre d'une négociation entre l'agent utilisateur et le
serveur.
- La période de la demande ; le monde évolue à travers le temps, les
représentations des ressources sont également susceptibles de changer
dans le temps.
En supposant qu'une représentation
a été récupérée avec succès, la puissance expressive du format de la
représentation affectera la précision avec laquelle le fournisseur de
représentation communique l'état de la ressource. Si la représentation
communique l'état de la ressource de façon inexacte, cette inexactitude ou
cette ambiguïté peut mener à une confusion pour les utilisateurs, à propos
de ce qu'est vraiment la ressource. Si les différents utilisateurs
aboutissent à des conclusions différentes à son sujet, ils peuvent alors
l'interpréter comme une collision
d'URI (§2.2.1). Certaines communautés, comme celle qui développe le
web sémantique, cherchent à fournir un framework pour communiquer la
sémantique exacte d'une ressource et ce d'une manière compréhensible par
une machine. La sémantique compréhensible par une machine peut lever une
partie de l'ambiguïté liée à la description des ressources en langage
naturel.
Une représentation est une donnée qui
encode l'information décrivant l'état d'une ressource. Les représentations
ne décrivent pas nécessairement la ressource. Elles ne dépeignent pas
forcement une image de la ressource ou ne représentent pas nécessairement
la ressource dans des sens différents de celui du mot "représente".
Les représentations d'une ressource
peuvent être envoyées ou reçues en utilisant des protocoles d'interaction.
Ces protocoles déterminent à leur tour sous quelle forme les
représentations sont véhiculées sur le Web. HTTP, par exemple, prévoit de
transmettre des représentations comme des flux d'octets, en les typant
avec des types de média Internet [RFC2046].
De la même
manière qu'il est important de réutiliser les schémas d'URI existants
chaque fois que possible, il y a des avantages significatifs à se servir
de flux d'octets typés pour des représentations, même dans le cas peu
courant de la définition d'un nouveau schéma d'URI et du protocole
associé. Par exemple, si le temps d'Oaxaca arrivait au navigateur de Nadia
par le biais d'un protocole différent de HTTP, alors le logiciel
responsable de l'affichage des formats tels que text/xhmtl+xml et
image/png serait toujours utilisable dans la mesure où le nouveau
protocole prendrait en compte la transmission de ces types. C'est un
exemple du principe des spécifications orthogonales (§5.1).
Bonne pratique : Réutiliser les formats de
représentation
Les nouveaux protocoles créés pour le web DEVRAIENT
transmettre les représentations en utilisant des flux d'octets typés avec
les types de média Internet.
Le
mécanisme de type de média Internet a quelques limites. Par exemple, le
type de média, chaîne de caractères, ne supporte ni les paramètres liés à
la gestion des versions (§4.2.1) ni
les autres paramètres. Voir les discussions du TAG à ce sujet : uriMediaType-9 et mediaTypeManagement-45 qui concernent des aspects de ce
mécanisme.
Le type de média Internet définit la syntaxe et la
sémantique de l'identifiant de fragment (introduit dans Identifiants de fragment (§2.6)). Il peut, le cas
échéant, être utilisé en conjonction d'une représentation.
Scénario
Dans une de ses pages XHTML, Dirk crée un lien hypertexte
vers une image que Nadia a publiée sur le Web. Il le crée en écrivant
<a href="http://www.example.com/images/nadia#hat">La chapeau
de Nadia</a>. Emma regarde la page XHTML de Dirk dans son
navigateur web et suit le lien. La mise en oeuvre HTML de son navigateur
supprime le fragment de l'URI puis demande l'image
"http://www.example.com/images/nadia". Nadia fournit une représentation
SVG de l'image (avec le type de média Internet "image/svg+xml"). Le
navigateur Web d'Emma démarre alors la mise en oeuvre SVG afin de voir
l'image. Il lui passe l'URI original, comprenant le fragment,
"http://www.example.com/images/nadia#hat", permettant ainsi de ne voir que
le chapeau et non l'image complète.
Notez que la mise en oeuvre HTML du navigateur d'Emma n'a
pas eu besoin de comprendre la syntaxe ou la sémantique du fragment SVG
(et inversement, l'outil SVG n'a pas besoin de comprendre la syntaxe de
fragment ou la sémantique HTML, WebCGM, RDF... ; il lui suffit de
reconnaître le délimiteur # de la syntaxe d'URI [ URI ] et d'enlever le
fragment pour accéder à la ressource). Cette orthogonalité (§5.1) est un fonctionnalité importante de
l'architecture du Web. En effet, c'est ce qui permet au navigateur d'Emma
de fournir un service utile sans pour autant exiger une mise à jour.
La sémantique d'un identifiant de fragment
est définie par l'ensemble des représentations qui pourraient résulter
d'une action de récupération de la ressource primaire. Le format et la
résolution du fragment dépendent donc du type de la représentation
potentiellement obtenue, même si une telle récupération n'est seulement
effectuée que si l'URI est déréférencé. Si aucune représentation n'existe,
alors la sémantique du fragment est considérée comme inconnue et, de fait,
sans contrainte. La sémantique de l'identifiant de fragment est
orthogonale au schéma d'URI et ne peut pas être redéfinie ainsi par une
spécification de schéma d'URI.
L'interprétation de l'identifiant de fragment est
seulement effectuée par l'agent qui déréférence un URI ; l'identifiant de
fragment n'est pas passé à d'autres systèmes pendant le processus de
récupération. Cela signifie que certains intermédiaires dans
l'architecture du web (comme les proxies) n'ont aucune interaction avec
les identifiants de fragment et que les redirections (dans HTTP [RFC2616] par exemple) ne s'appliquent pas
aux fragments.
La négociation de contenu
consiste à fournir de multiples représentations par l'intermédiaire d'un
même URI. La négociation, entre l'agent émetteur de la requête et le
serveur, détermine quelle représentation est servie (habituellement avec
pour objectif de servir la "meilleure" représentation pouvant être traitée
par un agent la recevant). HTTP est un exemple de protocole qui permet à
des fournisseurs de représentation d'utiliser la négociation de
contenu.
Les différents formats de
données peuvent définir leurs propres règles pour l'usage de la syntaxe de
l'identifiant de fragment afin de spécifier différents types de
sous-ensembles, de vues ou de références externes qui sont identifiables,
par ce type de média, en tant que ressources secondaires. Par conséquent,
les fournisseurs de représentations doivent contrôler soigneusement la
négociation de contenu lorsqu'elle est utilisée avec un URI qui contient
un identifiant de fragment. Considérons un exemple dans lequel le
propriétaire de l'URI "http://weather.example.com/oaxaca/map#zicatela"
emploie la négociation de contenu pour délivrer deux représentations de la
ressource identifiée. Trois cas sont possibles :
- L'interprétation de "zicatela" est définie de façon consistante
par les spécifications des deux formats de données. Le fournisseur de
la représentation décide quand les définitions de la sémantique de
l'identifiant de fragment sont suffisamment cohérentes.
- L'interprétation de "zicatela" est définie de façon inconsistante
par les spécifications des formats de données.
- L'interprétation de "zicatela" est définie dans une spécification
de format de données mais pas dans l'autre.
La première situation (où la
sémantique est consistante) ne pose aucun problème.
Le deuxième cas est une erreur de gestion du serveur : les
fournisseurs de représentations ne doivent pas utiliser la négociation de
contenu pour servir des formats de représentation dont la sémantique de
l'identifiant de fragment est inconsistant. Cette situation conduit
également à une collision d'URI
(§2.2.1).
Le troisième cas n'est
pas une erreur de gestion du serveur. C'est un moyen pour le Web de se
développer. Puisque le Web est un système réparti dans lequel des formats
et des agents sont déployés d'une façon non-uniforme, l'architecture du
web ne contraint pas les auteurs à utiliser que des formats "ayant le plus
petit dénominateur commun". Les auteurs de contenu peuvent tirer profit de
nouveaux formats de données tout en s'assurant toujours d'une
compatibilité ascendante raisonnable pour les agents qui ne les mettent
pas encore en oeuvre.
Dans le
troisième cas, le comportement de l'agent réceptionnant peut changer en
fonction de la définition éventuelle, par le format négocié, de la
sémantique de l'identifiant de fragment. Quand un format de données reçu
ne définit pas cette sémantique, l'agent ne devrait pas passer sous silence la reprise sur erreur
à moins que l'utilisateur ait donné son consentement ; voir [CUAP] pour la suggestion de comportements
complémentaires de l'agent dans ce cas précis.
Voir les discussions associées du TAG, RDFinXHTML-35.
Une communication
réussie entre deux parties dépend d'une compréhension raisonnablement
partagée de la sémantique des messages échangés, non seulement au niveau
des données mais également au niveau des métadonnées. Parfois, il peut y
avoir des contradictions entre les données et les métadonnées d'un
expéditeur de message. Voici des exemples, observés dans la pratique, de
ce type d'inconsistance sont :
- L'encodage réel des caractères d'une représentation (par exemple,
"iso-8859-1", spécifié par l'attribut
encoding dans une
déclaration XML) est contradictoire avec le paramètre du jeu de
caractères présent dans les métadonnées de la représentation (par
exemple, "utf-8", indiqué par le champ "Content-Type" dans un en-tête
HTTP).
- L'espace de noms
(§4.5.3) de l'élément racine des données XML d'une représentation
(par exemple, celui spécifié par l'attribut "xmlns") est
contradictoire avec la valeur du champ "Content-Type" dans un en-tête
HTTP.
D'un autre côté, il n'y a aucune
contradiction à servir un contenu HTML en ayant un type de média
"text/plain", par exemple, car cette combinaison est autorisée par les
spécifications.
Les agents récepteurs
devraient détecter les inconsistances liées au protocole et gérer une reprise sur erreur
appropriée.
Contrainte: Inconsistance des
données/métadonnées
Les agents NE DOIVENT PAS ignorer les métadonnées des
messages sans le consentement de l'utilisateur.
Ainsi, par exemple, si les responsables du site
"weather.example.com" marquent de manière erronée la photo satellite
d'Oaxaca avec le type "image/gif" au lieu de "image/jpeg" et si le
navigateur de Nadia détecte un problème, il ne doit pas l'ignorer (en
affichant simplement l'image JPEG par exemple) sans le consentement de
Nadia. Le navigateur de Nadia peut l'informer du problème ou peut non
seulement l'en informer mais aussi prendre une mesure corrective.
En outre, les fournisseurs de
représentation peuvent aider à réduire le risque d'inconsistance en
attribuant soigneusement les métadonnées de la représentation (en
particulier celles qui s'appliquent à plusieurs représentations). La
section sur les types de média
pour XML (§4.5.7) présente un exemple permettant de réduire le risque
d'erreur, en ne fournissant aucune métadonnée concernant l'encodage de
caractères lorsqu'il s'agit de délivrer du XML.
L'exactitude des métadonnées repose sur les
administrateurs du serveur, les auteurs des représentations et le logiciel
qu'ils utilisent. En pratique, les possibilités des outils et les
relations sociales peuvent être des facteurs limitants.
L'exactitude de ces dernières et des autres
champs de métadonnées est aussi importante pour les ressources dynamiques
du Web, où un peu de réflexion et de programmation peuvent souvent assurer
des métadonnées correctes pour un grand nombre de ressources.
Il y a souvent une séparation de contrôle entre
les utilisateurs qui créent des représentations de ressources et les
gestionnaires de serveur qui maintiennent le logiciel du site Web. Ceci
étant dit, le logiciel du site web est généralement à l'origine des
métadonnées qui sont associées à une ressource. Il en résulte qu'une
coordination entre les gestionnaires de serveur et les créateurs de
contenu est nécessaire.
Bonne pratique : Association de métadonnées
Les gestionnaires de
serveur DEVRAIENT permettre aux créateurs de représentation de contrôler
les métadonnées liées à leurs représentations.
En particulier, les créateurs de contenu doivent pouvoir
définir le type de contenu (pour l'extensibilité) et l'encodage des
caractères (pour une internationalisation appropriée).
Les conclusions du TAG, "métadonnées qui font autorité [Authoritative
Metadata]", abordent plus en détail la façon de traiter la
consistance données/métadonnées et la façon dont la configuration d'un
serveur peut être employée pour l'éviter.
L'obtention par Nadia d'informations sur le temps (un
exemple de requête en lecture seule ou d'une recherche) est qualifiée d'interaction
sûre. Une interaction sûre implique que l'agent ne provoque
aucune obligation en dehors de l'interaction. Un agent peut provoquer des
obligations par d'autres moyens (comme par la signature d'un contrat). Si
un agent n'a pas d'engagement avant une interaction sûre, il ne doit pas
en avoir après.
D'autres interactions
web ressemblent plus à des ordres qu'à des questions. Ces interactions non sûres
peuvent induire un changement d'état d'une ressource et l'utilisateur peut
être jugé responsable des conséquences de ces interactions. Les
interactions non sûres incluent la souscription à une lettre d'actualité,
l'envoi de message à une liste ou la modification d'une base de données.
Note : Dans ce contexte, le mot "non sûr" ne signifie pas
nécessairement "dangereux". Le terme "sûr" est employé dans la section
9.1.1 de la [RFC2616] et le terme "non
sûr" constitue son opposé naturel.
Scénario
Nadia décide de réserver
des vacances à Oaxaca via "booking.example.com". Elle saisit des données
dans une série de formulaires en ligne et finalement les informations
relatives à sa carte de crédit lui sont demandées, pour pouvoir acheter
les billets d'avion. Elle les fournit dans un autre formulaire. Quand elle
appuie sur le bouton "acheter", son navigateur ouvre une autre connexion
réseau au serveur "booking.example.com" et envoie, en utilisant la méthode
POST, un message avec des données issues du formulaire. C'est une interaction non sûre.
Nadia souhaite changer l'état du système en échangeant de l'argent contre
des billets d'avion.
Le serveur lit la
requête POST et, après l'exécution de la transaction de réservation,
renvoie un message au navigateur de Nadia qui contient une représentation
des résultats de sa demande. Les données de la représentation sont en
XHTML de sorte que Nadia puisse les sauver ou les imprimer.
Notez que ni les données transmises par POST, ni
les données reçues dans la réponse ne correspondent nécessairement à une
ressource identifiée par un URI.
Les interactions sûres sont importantes parce que ce sont
des interactions parmi lesquelles les utilisateurs peuvent naviguer en
toute confiance et où les agents (en incluant les moteurs de recherche et
les navigateurs qui mettent en cache des données pour l'utilisateur)
peuvent suivre des liens hypertextes sans risque. Les utilisateurs (ou les
agents agissant en leur nom) ne s'engagent à rien en demandant une
ressource ou en suivant un lien hypertexte.
Principe: Récupération
sûre
Les
agents ne s'engagent pas en récupérant une représentation.
Par exemple, il est incorrect de publier
un URI qui contient des informations (une partie de l'URI) permettant
d'inscrire un utilisateur à une liste de discussions. Rappelez-vous que
les moteurs de recherche peuvent suivre de tels liens hypertextes.
Le fait qu'un GET HTTP, la méthode d'accès
la plus souvent utilisée pour suivre un lien hypertexte, soit sûre
n'implique pas que toutes les interactions sûres doivent être faites via
des GET HTTP. Parfois, il peut y avoir de bonnes raisons (comme pour des
besoins de confidentialité ou des limites pratiques quant à la longueur
des URI) de mener une opération sûre, par un autre moyen, en utilisant un
mécanisme généralement réservé aux opérations non sûres (par exemple, un
POST HTTP).
Pour plus d'informations
sur les opérations sûres et non sûres employant les méthodes GET et POST
de HTTP ainsi que sur les aspects de traitement de la sécurité liés à
l'utilisation du GET HTTP, reportez-vous aux conclusions du TAG :
"URI, possibilité d'adressage et utilisation des commandes
HTTP GET et POST [URIs, Addressability, and the use of HTTP GET and
POST]".
Scénario
Nadia paie ses billets d'avion en ligne (par une
interaction POST comme décrit ci-dessus). Elle reçoit une page web avec
l'information de confirmation et souhaite la mettre dans ses favoris de
sorte qu'elle puisse s'y référer quand elle calculera ses dépenses. Bien
que Nadia puisse imprimer ces résultats ou encore les sauvegarder dans un
fichier, elle voudrait également pouvoir les conserver en tant que
favori.
Les requêtes et
les résultats de transaction sont des ressources à valeur ajoutée et comme
toutes les ressources de ce type, il est utile de pouvoir s'y rapporter à
l'aide d'un URI persistant
(§3.5.1). Cependant, dans la pratique, Nadia ne peut pas conserver sa
confirmation de paiement (exprimée par l'intermédiaire d'une requête POST)
ni la confirmation de la compagnie aérienne ni même l'engagement qu'une
place lui est réservée (exprimé par l'intermédiaire de la réponse au
POST).
Il existe des solutions pour
fournir des URI persistants pour des requêtes de transaction et pour leurs
résultats. Pour les requêtes, les agents utilisateur peuvent fournir une
interface de gestion des transactions où l'agent utilisateur s'est engagé
au nom de l'utilisateur. Pour les résultats de transaction, HTTP permet
aux fournisseurs de représentation d'associer un URI aux résultats d'une
requête POST HTTP en utilisant l'en-tête de "Content-Location" (décrit
dans section 14.14 de la [RFC2616]).
Scénario
Comme Nadia trouve le site
indiquant le temps d'Oaxaca utile, elle envoie son point de vue, par
courrier électronique, à son ami Dirk en lui recommandant de regarder
'http://weather.example.com/oaxaca'. Dirk clique sur le lien hypertexte
apparaissant dans le courriel qu'il reçoit mais une erreur 404 (non
trouvé) le frustre. Dirk essaie de nouveau le jour suivant et reçoit une
représentation avec des "nouvelles" vieilles de deux semaines. Il essaie
une fois de plus le jour suivant et obtient une représentation clamant que
le temps à Oaxaca est ensoleillé, alors que ses amis y habitant lui disent
par téléphone, qu'en fait, il pleut. Dirk et Nadia concluent que les
propriétaires de l'URI ne sont pas fiables ou sont imprévisibles. Bien que
le propriétaire de cet URI ait choisi le web comme moyen de communication,
il vient de perdre deux clients à cause d'une gestion inefficace de ses
représentations.
Un
propriétaire d'URI peut fournir plusieurs représentations officielles de
la ressource identifiée par cet URI, ou bien aucune. Fournir des
représentations bénéficie cependant à la communauté.
Bonne pratique : Disponibilité des
représentations
Un propriétaire d'URI DEVRAIT fournir des représentations
de la ressource qu'il identifie.
Par exemple, les propriétaires des URI d'espace de noms
XML devraient les utiliser pour identifier un document d'espace de noms
(§4.5.4).
La disponilité de
représentations ne signifie pas qu'il est toujours souhaitable de les
récupérer. En fait, dans certains cas, c'est l'inverse.
Principe: La référence n'implique pas la
déréférence
Un développeur d'application ou un auteur de
spécifications NE DEVRAIT PAS avoir besoin de récupérer les
représentations à travers le réseau chaque fois qu'elles sont
référencées.
Déréférencer un
URI induit un coût (potentiellement significatif) au niveau des ressources
informatiques et de la bande passante. Cela peut avoir des implications du
point de vue de la sécurité et peut imposer une latence significative à
l'application qui déréférence. Les URI déréférencés devraient être évités
sauf lorsqu'ils sont nécessaires.
Les
sections suivantes abordent quelques aspects de la gestion des
représentations, comme la promotion de la persistance d'URI (§3.5.1), la gestion de l'accès aux ressources (§3.5.2) et le support de la navigation
(§3.5.3).
Comme c'est le cas pour beaucoup d'interactions
humaines, la confiance dans les interactions via le web dépend de la
stabilité et de la prévisibilité. Pour une ressource d'information, la
persistance dépend de la consistance des représentations. Le fournisseur
de représentations décide lorsqu'elles sont suffisamment consistantes
(même si cette détermination tient compte généralement des attentes des
utilisateurs).
Bien que l'on puisse
dans ce cas observer la persistance comme le résultat de l'obtention d'une
représentation, le terme persistance d'URI est utilisé
pour décrire une propriété vraiment souhaitable : un URI, une fois associé
à une ressource, devrait continuer indéfiniment à se référer à cette
ressource.
Bonne pratique : Représentation
consistante
Un propriétaire d'URI DEVRAIT fournir des représentations
consistantes et prédictibles de la ressource identifiée.
La persistance d'URI est une question de
politique et d'engagement de la part du propriétaire d'URI. Le choix d'un schéma particulier
d'URI ne garantit pas que ces URI seront persistants ou qu'ils ne le
seront pas.
HTTP [RFC2616] a été conçu pour aider au contrôle de la
persistance d'URI. Par exemple, la redirection HTTP (utilisant les codes
de réponse 3xx) permet à des serveurs d'indiquer à un agent qu'il doit
prendre d'autres mesures pour finaliser la requête (par exemple, un nouvel
URI est associé à la ressource).
En
outre, la négociation de contenu
favorise également la consistance, car un gestionnaire de site n'est pas
dans l'obligation de définir de nouveaux URI lorsqu'il ajoute le support
d'une nouvelle spécification de format. Les protocoles, qui ne prennent
pas en compte la négociation de contenu (tel que FTP), exigent un nouvel
identifiant lors de l'introduction d'un nouveau format de données. La
mauvaise utilisation de la négociation de contenu peut aboutir à des
représentations inconsistantes.
Le
document [Cool] présente davantage
d'échanges au sujet de la persistance d'URI.
Il est raisonnable de limiter l'accès à une ressource
(pour des raisons commerciales ou de sécurité, par exemple). Mais,
l'identification d'une ressource se rapproche simplement de celle d'un
livre par son titre. Dans des circonstances exceptionnelles, les personnes
peuvent s'entendre pour maintenir des titres ou des URI confidentiels
(par exemple, un auteur de livre et un éditeur peuvent se mettre d'accord
pour garder secret l'URI de la page, contenant des informations
complémentaires, jusqu'à l'édition du livre). Dans le cas contraire, ces
titres et ces URI sont librement échangeables.
Voici une analogie : Les propriétaires d'un bâtiment
pourraient avoir une politique stipulant que le public ne peut entrer dans
le bâtiment que par l'intermédiaire de la porte principale et seulement
pendant les heures de bureau. Ceux qui travaillent dans le bâtiment et qui
effectuent des livraisons pourraient se servir d'autres portes plus
appropriées. Une telle politique serait renforcée par une sécurité
effectuée par le personnel ainsi que par des dispositifs mécaniques tels
que des serrures et des passages contrôlés par des cartes d'accès. Mettre
en place cette politique ne requiert pas de cacher certaines entrées du
bâtiment, ni de demander à la législation l'utilisation obligatoire de la
porte principale et d'interdire toute autre porte d'accès au bâtiment.
Scénario
Nadia envoie à Dirk l'URI de l'article qu'elle est en
train de lire. Avec son navigateur, Dirk suit le lien hypertexte et est
invité à s'identifier en saisissant son nom d'utilisateur et son mot de
passe. Dirk étant également un abonné des services fournis par
"weather.example.com", il peut accéder aux mêmes informations que Nadia.
Ainsi, l'autorité contrôlant "weather.example.com" peut limiter l'accès
aux personnes autorisées et continuer à fournir les avantages des URI.
Le web fournit plusieurs
mécanismes pour contrôler l'accès aux ressources ; ces mécanismes ne se
basent pas sur le masquage ou la suppression des URI de ces ressources.
Pour plus d'informations, voir les conclusions du TAG "Lien
en profondeur dans le World Wide Web ["Deep Linking" in the World Wide
Web]".
La possibilité de faire et de partager des liens est une
force de l'architecture du Web. Un utilisateur, qui a trouvé une partie
intéressante du Web, peut partager cette expérience simplement en
republiant un URI.
Scénario
Nadia et Dirk veulent
visiter le musée des prévisions météorologiques dans Oaxaca. Nadia se rend
sur "http://maps.example.com", localise le musée et expédie par courriel
l'URI "http://maps.example.com/oaxaca?lat=17.065;lon=-96.716;scale=6" à
Dirk. Dirk se rend sur "http://mymaps.example.com", localise le musée et
envoie, par courriel également, l'URI
"http://mymaps.example.com/geo?sessionID=765345;userID=Dirk" à Nadia. Dirk
lit le message de Nadia et peut suivre le lien vers la carte. Nadia lit
celui de Dirk, suit le lien mais reçoit un message d'erreur
'session/utilisateur inexistant'. Nadia doit recommencer à partir de
"http://mymaps.example.com" et trouver l'emplacement du musée une fois de
plus.
Pour les
ressources qui sont produites à la demande, la génération des URI par la
machine est simple. Par contre, les gestionnaires de serveur devraient
éviter de limiter inutilement la réutilisabilité des URI de ressources
qu'il pourrait être utile de garder dans des signets pour une lecture
postérieure ou utile de partager avec d'autres. Si l'intention est de
limiter l'information à un utilisateur particulier, comme par exemple dans
le cas d'une application d'opérations bancaires pour les particuliers, les
concepteurs devraient employer les mécanismes appropriés du contrôle d'accès (§3.5.2).
Les interactions à base de POST HTTP (où le GET
HTTP aurait pu être utilisé) limitent également les possibilités de
navigation. L'utilisateur ne peut pas créer de signet ou partager l'URI
car, les transactions ne fournissent pas d'URI différents de celui utilisé
par l'utilisateur pour interagir avec le site.
Certaines questions
concernant les interactions du web restent en suspens. Le TAG prévoit que
les futures versions de ce document aborderont plus en détail les
relations entre l'architecture décrite ci-dessus, les services Web, les
systèmes point-à-point, les systèmes de messagerie instantanée (comme [RFC3920]), la lecture de flux audio
(telle que RTSP [RFC2326]) et la voix
sur IP (tel que SIP [RFC3261]).
Une spécification de format de données (par exemple, pour
XHTML, RDF/XML, SMIL, XLink, CSS et PNG) est l'incarnation d'un accord sur
l'interprétation correcte des données de représentation. Le premier format de données utilisé sur
le web était HTML. Depuis, les formats de données se sont multipliés.
L'architecture du web ne contraint pas les fournisseurs de contenu sur la
nature des formats qu'ils peuvent employer. Cette flexibilité est
importante car il existe une évolution constante dans les applications, ce
qui implique de nouveaux formats de données et l'amélioration des formats
existants. Bien que l'architecture du web tienne compte du déploiement de
nouveaux formats de données, leur création (ainsi que celle des agents
capables de les manipuler) est coûteuse. Avant d'inventer un nouveau
format de données (ou un format "méta" tel que XML), les concepteurs
devraient donc soigneusement considérer la réutilisation de ce qui est
déjà disponible.
Pour qu'un format de
données soit interopérable de façon utile entre deux parties, ces parties
doivent s'accorder (jusqu'à un degré raisonnable) au sujet de sa syntaxe
et de sa sémantique. La compréhension mutuelle d'un format de données
favorise l'interopérabilité mais n'implique pas de contraintes sur
l'utilisation. Par exemple, un expéditeur de données ne peut pas compter
sur le fait de pouvoir contraindre le comportement d'un récepteur de ces
données.
Nous décrivons, ci-dessous,
certaines caractéristiques d'un format de données qui facilitent
l'intégration dans l'architecture du Web. Ce document ne se préoccupe pas
des avantages généraux d'une spécification tels que la lisibilité, la
simplicité, la considération des objectifs du programmeur, la
considération des besoins de l'utilisateur, l'accessibilité, ni
l'internationalisation. La section sur les spécifications liées à l'architecture (§7.1) inclut des
références à des directives complémentaires pour la spécification de
format.
Les formats de données binaires sont ceux dans
lesquels des parties de données sont codées pour un usage direct par un
processeur d'ordinateur, comme par exemple les représentations
petit-boutistes 32 bits à complément à deux [ndt. Little-endian] et les
nombres IEEE, sur 64 bits, à virgule flottante en double précision. Les
parties de données ainsi représentées incluent des valeurs numériques, des
pointeurs et des données compressées de toutes sortes.
Dans un format de données textuel, les données sont
spécifiées comme étant une séquence de caractères dans un encodage défini.
Le HTML, les courriels Internet et tous les formats de données basés sur XML (§4.5) sont des formats
textuels. De plus en plus, ces formats internationalisés se réfèrent au
répertoire Unicode [UNICODE] pour la
définition de caractères.
Le fait
qu'un format de données soit textuel, tel qu'il est défini dans cette
section, n'implique pas qu'il doive être servi avec un type de média
commençant par "text/". Même si les formats basés sur XML sont textuels,
beaucoup d'entre eux ne consistent pas en des expressions en langage
naturel. Voir la section sur les types de média pour XML (§4.5.7) qui aborde les problèmes
surgissant lorsque "text/" est utilisé en conjonction avec un format basé
sur XML.
En principe, toutes les
données peuvent être représentées en utilisant des formats textuels. Dans
la pratique, quelques types de contenu (par exemple, l'audio et la vidéo)
sont généralement représentés en utilisant des formats binaires.
Les différences entre les formats de données
binaires et textuels sont complexes et dépendantes des applications. Les
formats binaires peuvent être substantiellement plus compacts, en
particulier pour les structures de données complexes, riches en pointeurs.
En outre, ils peuvent être consommés plus rapidement par les agents
puisqu'ils peuvent être chargés en mémoire et employés avec peu ou pas de
conversion. Notons, cependant, que de tels cas sont relativement rares car
ce type d'utilisation directe peut ouvrir la porte à des problèmes de
sécurité solubles, de façon pratique, qu'en examinant en détail chaque
aspect de la structure de données.
Les
formats textuels sont habituellement plus portables et interopérables. Ils
ont également l'avantage considérable de pouvoir être directement lus par
les êtres humains (et même compris grâce à une documentation suffisante).
Cela peut simplifier les tâches de création et de maintenance du logiciel
et permettre une intervention humaine directe dans la chaîne de
traitements, sans besoin d'avoir recours à des outils plus complexes qu'un
simple éditeur de texte. Enfin, ils simplifient la tâche, nécessaire à
chaque personne, d'apprentissage de nouveaux formats de données. On
appelle ça l'effet "voir la source".
Il est important de souligner que les idées préconçues
quant à la taille des données et la vitesse de traitement n'est pas un
guide fiable dans la conception de format de données. Les études
quantitatives sont essentielles pour une meilleure compréhension des
différences. Par conséquent, les concepteurs de spécification de format de
données devraient faire un choix considéré entre la conception d'un format
binaire et celle d'un format textuel.
Voir les discussions du TAG à propos de binaryXML-30.
Dans un monde
parfait, les langages seraient conçus de façon à répondre parfaitement aux
besoins exprimés, ces besoins représenteraient un modèle parfait du monde,
ils ne changeraient jamais au fil du temps et toutes les mises en oeuvre
seraient parfaitement interopérables car les spécifications ne seraient
sujet à aucune variabilité.
Dans le
monde réel, les concepteurs répondent de façon imparfaite aux besoins, car
ils les interprètent. Ces besoins modélisent le monde de façon inexacte.
Qui plus est, certains besoins sont contradictoires et changent avec le
temps. Par conséquent, les concepteurs négocient avec les utilisateurs,
font des compromis et introduisent souvent des mécanismes d'extensibilité
afin de pouvoir contourner les problèmes à court terme. À long terme, ils
produisent de multiples versions de leur langage, à mesure que le problème
et leur compréhension du problème évoluent. La variabilité induite dans
les spécifications, les langages et les mises en oeuvre introduisent des
coûts d'interopérabilité.
L'extensibilité et la gestion des versions sont des
stratégies permettant d'aider à contrôler l'évolution naturelle de
l'information sur le web et des technologies utilisées pour la
représenter. Pour plus d'informations sur la façon dont ces stratégies
introduisent de la variabilité et la façon dont cette variabilité a des
impacts sur l'interopérabilité, voir Variabilité dans les spécifications [Variability in
Specifications].
Voir les
discussions du TAG XMLVersioning-41, qui concernent les bonnes pratiques
pour concevoir des langages XML extensibles et pour gérer les versions.
Voir également l'"Architecture du Web : langages extensibles" [EXTLANG].
Il y a typiquement une
(longue) période de transition durant laquelle de multiples versions d'un
format, d'un protocole ou d'un agent sont simultanément en service.
Bonne pratique : Information à propos des
versions
Une spécification de format de données DEVRAIT fournir des
informations relatives à la version.
Scénario
Nadia et Dirk conçoivent un
format de données XML pour encoder des données au sujet de l'industrie du
film. Ils fournissent une certaine extensibilité en utilisant des espaces
de noms XML et en créant un schéma qui permet l'inclusion, dans certains
endroits, d'éléments appartenant à d'autres espaces de noms. Quand ils
mettent à jour leur format, Nadia propose un nouvel attribut facultatif,
lang, sur l'élément film. Dirk estime qu'après
un tel changement, ils se doivent d'assigner un nouvel espace de nom, qui
pourrait demander des changements aux logiciels déployés. Nadia explique à
Dirk que leur choix stratégique d'extensibilité associé à leur politique
d'espace de noms autorise certains changements, qui n'affectent pas la
conformité du contenu et des logiciels existants. Aucun changement de
l'identifiant d'espace de noms n'est alors nécessaire. Le choix de cette
politique doit les aider à atteindre leurs objectifs de réduction des
coûts relatifs au changement.
Dirk et Nadia ont choisi une politique d'évolution de
l'espace de noms qui leur permet d'éviter de le changer à chaque fois
qu'ils font des modifications qui n'affectent pas la conformité du contenu
et des logiciels déployés. Ils pourraient très bien avoir choisi une
politique différente. Par exemple, tout nouvel élément ou attribut doit
appartenir à un espace de noms différents de l'original. Quelque soit la
politique choisie, elle doit fixer clairement les règles pour les
utilisateurs du format.
En général, le
changement de l'espace de noms d'un élément change totalement le nom
d'élément. Si "a" et "b" sont associés à deux URI différents,
a:element et b:element sont aussi distincts que
a:eieio et a:xyzzy. Dans la pratique, cela
signifie que les applications déployées devront être mises à jour afin de
reconnaître ce nouveau langage. Le coût induit peut être très élevé.
Ce qui implique qu'il y a des compromis
significatifs à considérer lors du choix de la politique d'évolution d'un
espace de noms. Si un vocabulaire ne vise pas l'extensibilité
(c'est-à-dire, s'il n'autorise pas des éléments ou des attributs provenant
d'espaces de noms étrangers ou s'il ne possède pas de mécanisme pour
traiter des noms inconnus appartenant au même espace de noms), il peut
être absolument nécessaire de changer le nom d'espace de noms. Les
langages qui permettent une certaine forme d'extensibilité sans exiger un
changement de nom d'espace de noms sont plus simples à faire évoluer de
façon élégante.
Bonne pratique : Politique
d'espace de noms
Une spécification de format XML DEVRAIT inclure des
informations sur la politique de changement concernant les espaces de noms
XML.
A titre d'exemple de
politique de changement conçue pour refléter la stabilité variable d'un
espace de noms, considérons la politique d'espace de noms du W3C appliquée aux documents
sur le chemin de la recommandation. La politique spécifie que le groupe de
travail responsable de l'espace de noms peut le modifier à volonté jusqu'à
un certain point dans le processus ("recommandation candidate"). À partir
de ce point, le W3C contraint l'ensemble des changements possibles de
l'espace de noms afin de promouvoir des mises en oeuvres stables.
Notez que, les noms d'espace de noms étant
des URI, le propriétaire de l'URI d'un espace de noms possède l'autorité
pour décider de la politique d'évolution de cet espace de noms.
Les besoins changent avec le temps. Les technologies qui
ont du succès sont adoptées et adaptées par de nouveaux utilisateurs. Les
concepteurs peuvent faciliter le processus de transition en étant
attentifs aux choix concernant l'extensibilité faits lors de la conception
d'une spécification d'un langage ou d'un protocole.
En faisant ces choix, les concepteurs doivent prendre la
mesure des différences entre extensibilité, simplicité et variabilité. Un
langage sans mécanismes permettant l'extension peut être plus simple et
moins variable, améliorant ainsi l'interopérabilité initiale. Cependant,
dans ce cas, il est probable que les changements à apporter à ce langage
seront plus difficiles, plus complexes et plus variables.
L'interopérabilité peut alors diminuer sur le long terme.
Bonne pratique : Mécanismes permettant
l'extension
Une spécification DEVRAIT fournir des mécanismes qui
permettent à n'importe quelle partie de créer des extensions.
L'extensibilité introduit de la
variabilité qui a un impact sur l'interopérabilité. Cependant, les moyens
ad hoc d'étendre des langages, qui n'ont aucun mécanisme d'extensibilité,
affectent aussi l'interopérabilité. Un critère clé de ces mécanismes,
fournis par les concepteurs de langage, est qu'ils permettent aux langages
de rester en conformité avec la spécification originale, ce qui est un
facteur d'accroissement probable de l'interopérabilité.
Bonne pratique : Conformité
d'extensibilité
L'extensibilité NE DOIT PAS interférer dans la conformité
à la spécification originale.
Les applications ont besoin de déterminer la stratégie
d'extension la plus appropriée pour une spécification. Par exemple, les
concepteurs d'applications, fonctionnant dans des environnements clos,
peuvent s'autoriser la définition d'une stratégie de gestion des versions
qui serait inapplicable à l'échelle du web.
Bonne pratique
: Extensions inconnues
Une spécification DEVRAIT définir le
comportement des agents face aux extensions non reconnues.
Deux stratégies ont émergé et sont
particulièrement utiles :
- "doit ignorer" : L'agent ignore tout contenu qu'il ne reconnaît
pas.
- "doit comprendre" : L'agent traite les balises inconnues comme des
conditions d'erreur.
Une approche de conception
performante pour un langage est de permettre l'une ou l'autre forme
d'extension, mais de les distinguer explicitement au niveau de la
syntaxe.
La demande à l'utilisateur
d'informations additionnelles et la recherche automatique de données à
partir de liens hypertextes disponibles représente des stratégies
complémentaires. D'autres, plus complexes, sont également possibles, comme
des stratégies mixtes. Par exemple, un langage peut inclure des mécanismes
afin de surcharger le comportement standard. Ainsi, un format de données
peut spécifier "doit ignorer" la sémantique mais également permettre des
extensions qui redéfinissent cette sémantique selon les besoins de
l'application (par exemple, avec "doit comprendre" la sémantique pour une
extension particulière).
L'extensibilité n'est pas gratuite. Fournir des leviers
pour l'extensibilité est l'un des nombreux besoins qui induit des coûts de
conception d'un langage. L'expérience suggère que les avantages à long
terme d'un mécanisme d'extensibilité bien pensé sont généralement
supérieurs aux coûts.
Voir “D.3
Extensibilité et extensions [Extensibility and Extensions]” dans [QA].
De
nombreux formats de données modernes incluent des mécanismes pour la
composition. Par exemple :
- Il est possible d'inclure des commentaires textuels dans plusieurs
formats d'image, tels que JPEG/JFIF. Bien que ces commentaires soient
embarqués dans les données, ils ne sont pas destinés à affecter
l'affichage de l'image.
- Il y a des formats de conteneur comme SOAP qui s'attendent à un
contenu composé d'espaces de noms multiples mais qui fournissent une
relation sémantique globale pour l'enveloppe de message et le
contenu.
- La sémantique de documents RDF combinés, contenant de multiples
vocabulaires, est bien définie.
En principe, ces relations peuvent
être mélangées et imbriquées de façon arbitraire. Un message SOAP, par
exemple, peut contenir une image SVG qui contient un commentaire RDF qui
se rapporte à un vocabulaire de termes permettant de décrire l'image.
Il est cependant bon de noter, que pour un
XML général, aucun modèle sémantique ne définit les interactions, dans les
documents XML, entre les éléments et/ou les attributs appartenant à une
multitude d'espaces de noms. Chaque application doit définir comment les
espaces de noms interagissent entre eux et quel effet l'espace de nom d'un
élément a sur les ancêtres, les frères et les descendants de
l'élément.
Voir les discussions du TAG
mixedUIXMLNamespace-33 (au sujet de la signification d'un
document composé d'un contenu provenant d'espaces de noms multiples), xmlFunctions-34 (au sujet d'une approche pour contrôler
la transformation et la possibilité de composer du XML) et RDFinXHTML-35 (au sujet de l'interprétation de RDF une
fois qu'il est incorporé dans un document XHTML).
Le web est un environnement hétérogène où une
grande variété d'agents permettent, à des utilisateurs, d'accéder à un
contenu via de multiples possibilités. C'est une bonne habitude pour des
auteurs de créer un contenu qui peut atteindre une audience la plus large
possible, que les utilisateurs soient équipés d'ordinateurs de bureau,
mais également de périphériques portables et de téléphones mobiles, ou
encore de dispositifs capables de prendre en charge une certaine
incapacité (comme des synthétiseurs vocaux ou d'autres inexistants à
l'heure actuelle). Qui plus est, dans certains cas, les auteurs ne peuvent
pas prévoir comment un agent affichera ou traitera leur contenu.
L'expérience prouve que la séparation du contenu, de la présentation et
des interactions favorise la réutilisation et l'indépendance du contenu
vis-à-vis d'un périphérique donné. Cette séparation suit le principe des
spécifications orthogonales
(§5.1).
Cette séparation facilite
également la réutilisation de contenu au travers de contextes de diffusion
multiples. Parfois l'expérience fonctionnelle des utilisateurs, quel que
soit le contexte de diffusion, peut être le fruit d'un processus
d'adaptation appliqué à une représentation indépendante du moyen d'accès.
Pour plus d'informations à propos des principes d'indépendance vis-à-vis
des périphériques, voir [DIPRINCIPLES].
Bonne pratique : Séparation du contenu, de la présentation
et des interactions
Une spécification DEVRAIT permettre à des auteurs de
séparer le contenu des aspects relatifs à la fois à la présentation et aux
interactions.
Notez que quand
la conception permet de séparer le contenu, la présentation et les
interactions, les agents doivent les recombiner. Il existe un spectre de
recombinaisons, allant de "le client fait tout" à "le serveur fait
tout".
Chaque approche possède ses
avantages. Par exemple, quand un client (comme un téléphone mobile)
communique les caractéristiques de son équipement au serveur (en utilisant
CC/PP, par exemple), le serveur peut fabriquer le contenu pour l'ajuster à
ce client. Par exemple, le serveur peut permettre des téléchargements plus
rapides en positionnant les liens vers des images ayant une résolution
inférieure, vers des vidéos plus petites voire en supprimant les liens
vers les vidéos. De même, si le contenu a été écrit avec des branches
multiples, le serveur peut enlever les branches inutilisées avant de
délivrer le contenu. En outre, en travaillant le contenu pour s'adapter
aux caractéristiques d'un client cible, le serveur peut favoriser la
réduction du temps de calcul côté client. Cependant, la spécialisation du
contenu de cette façon réduit l'efficacité des techniques de cache.
D'un autre côté, concevoir un contenu
pouvant être recombiné sur le client tend également à rendre ce contenu
applicable à un éventail plus large de périphériques. Cette conception
améliore également l'efficacité du système de cache et offre à des
utilisateurs plus d'options quant à la présentation. Des feuilles de style
dépendantes du média peuvent être utilisées pour fabriquer le contenu, au
niveau client, pour des groupes particuliers de périphériques cibles. Pour
un contenu textuel avec une structure régulière et récurrente, la taille
combinée du contenu et de sa feuille de modèle est typiquement moins
importante que le contenu entièrement recombiné ; l'amélioration est
encore plus grande, si la feuille de style est réutilisée par d'autres
pages.
En pratique, une combinaison
des deux approches est souvent utilisée. La décision conceptuelle de
localiser une application dans ce spectre dépend de la puissance du
client, de la puissance et de la charge du serveur et de la largeur de
bande passante du médium qui les relie. Si le nombre de clients possibles
est illimité, l'application gagnera en montée en charge, en déportant plus
de calculs sur le poste client.
Evidemment, il peut ne pas être souhaitable d'atteindre un
public le plus vaste possible. Les concepteurs devraient considérer les
technologies appropriées, telles que le chiffrage et le contrôle d'accès (§3.5.2), pour limiter
l'audience.
Certains formats de
données sont conçus pour décrire la présentation (comme SVG et les objets
de mise en forme XSL, XSL-FO). Les formats de ce type démontrent qu'on ne
peut séparer que le contenu de la présentation (ou de l'interaction) ; à
un certain, point il devient nécessaire de parler de la présentation. En
vertu des principes de spécifications orthogonales (§5.1), ces formats de
données devraient seulement aborder les questions de présentation.
Voir les discussions du TAG, formattingProperties-19 (au sujet de l'interopérabilité
dans le cas des propriétés et des noms de formatage) et contentPresentation-26 (au sujet de la séparation des
balises sémantiques de celles relatives à la présentation).
Le fait
qu'il soit possible d'inclure des références vers d'autres ressources par
l'intermédiaire des URI est une caractéristique qui définit le web. La
simplicité pour créer des liens hypertextes en utilisant des URI absolus
(<a href="http://www.example.com/foo">) et des
références à des URI relatifs (<a href="foo"> et
<a href="foo#anchor">) est en partie (et peut-être en
grande partie) responsable du succès du web hypertexte tel que nous le
connaissons aujourd'hui.
Quand une
représentation d'une ressource contient une référence à une autre
ressource, exprimée avec un URI identifiant cette autre ressource, cela
constitue un lien entre
les deux ressources. Des métadonnées complémentaires peuvent également
faire partie du lien (voir [XLink10]
par exemple). Note : Dans ce document, le terme "lien"
signifie généralement "relation" et non "connexion physique".
Bonne pratique : Identification de lien
Une spécification DEVRAIT
fournir des manières d'identifier des liens vers d'autres ressources, y
compris vers les ressources secondaires (par l'intermédiaire
d'identifiants de fragment).
Les formats qui permettent aux auteurs de contenu
d'utiliser des URI à la place d'identifiants locaux favorisent l'effet de
réseau : la valeur de ces formats se développe avec la taille du web
déployé.
Bonne pratique : Faire des liens vers le Web
Une spécification
DEVRAIT permettre des liens à l'échelle du Web et non uniquement à
l'intérieur d'un document.
Bonne pratique : URI
Générique
Une spécification DEVRAIT permettre aux auteurs de contenu
d'utiliser des URI sans qu'ils soient contraints à un ensemble limité de
schémas d'URI.
L'exploitation
des liens hypertextes par les agents n'est pas contrainte par
l'architecture du web et peut dépendre du contexte de l'application. Les
utilisateurs des liens hypertextes s'attendent à pouvoir naviguer parmi
les représentations en suivant des liens.
Bonne pratique
: Liens hypertextes
Un format de données DEVRAIT incorporer des
liens hypertextes si le paradigme attendu de l'interface utilisateur est
hypertexte.
Les formats de
données qui ne permettent pas aux auteurs de contenu de créer des liens
hypertextes conduisent à la création "de noeuds terminaux" sur le web.
Les
liens sont généralement exprimés en utilisant des références d'URI (définies dans la section
4.2 de [URI]), qui peuvent être combinées
avec un URI de base pour fournir un URI exploitable. La section 5.1 de [URI] explique différentes façons d'établir un
URI de base pour une ressource et d'établir une priorité parmi eux. Par
exemple, l'URI de base peut être un URI pour la ressource ou bien elle
peut être spécifiée dans une représentation (voir les éléments
base fournis par HTML et XML et l'en-tête HTTP
'Content-Location'). Voir également la section sur les liens en XML (§4.5.2).
Les agents résolvent une référence d'URI avant
d'employer l'URI réel pour interagir avec un autre agent. Les références
d'URI aident dans la gestion de contenu en permettant aux auteurs de
concevoir une représentation localement, c'est-à-dire, sans se soucier de
l'identifiant global qui pourra être employé plus tard pour se référer à
la ressource associée.
De nombreux formats de
données sont basés sur
XML, c'est-à-dire qu'ils se conforment aux règles de syntaxe
définies dans les spécifications XML [XML10] ou [XML11].
Cette section discute de points spécifiques à de tels formats. Quiconque
cherche des conseils dans ce secteur est invité à consulter les
"directives pour l'usage de XML dans les protocoles IETF" [IETFXML], qui contient une discussion
complète relative aux choix d'utiliser ou de ne pas utiliser XML, ainsi
que des directives spécifiques sur la façon dont il doit être employé.
Même si le document concerne les applications Internet avec des références
spécifiques aux protocoles, la discussion est généralement tout aussi
applicable aux scénarios du Web.
La
présente discussion devrait être vue comme un auxiliaire au document [IETFXML]. Référez-vous également aux
"directives d'accessibilité XML" [XAG]
pour une aide à la conception de formats XML qui minimisent les barrières
à l'accessibilité du web pour des personnes handicapées.
XML définit des formats de données textuels qui
sont naturellement adaptés à la description des objets de données
hiérarchiques et traités dans un ordre choisi. C'est largement, mais non
universellement, applicable pour des formats de données. Par exemple, un
format audio ou vidéo est peu susceptible d'être bien adapté à une
expression en XML. Les contraintes de conception qui suggéreraient
l'utilisation de XML sont :
- Nécessité d'une structure hiérarchique.
- Besoin d'un éventail d'outils important sur diverses
plates-formes.
- Besoin de données qui peuvent survivre aux applications qui les
traitent actuellement.
- Capacité de supporter l'internationalisation d'une façon qui se
décrit elle-même et qui supprime la confusion à propos des options de
codage.
- Détection précoce des erreurs d'encodage ne nécessitant pas de
trouver une "solution de contournement" pour ce genre d'erreurs.
- Une forte proportion à fournir un contenu textuel lisible pour
l'homme.
- Composition potentielle du format de données avec d'autres formats
encodés en XML.
- Le désir d'avoir des données facilement analysables par les hommes
et les machines.
- Le désir d'avoir des vocabulaires pouvant être inventés d'une
façon distribuée et combinés avec souplesse.
Les mécanismes de liaison sophistiqués ont été inventés
pour les formats XML. XPointer permet de faire des liens vers un contenu
qui ne possède pas d'ancre nommée explicite. [XLink] est une spécification appropriée pour représenter
des liens dans des applications hypertextes (§4.4) XML. XLink permet aux liens d'avoir
des extrémités multiples et d'être exprimés soit en ligne soit via des
"bases de liens" stockées à l'extérieur de tout ou partie des ressources
identifiées par les liens qu'elles contiennent.
Les concepteurs de formats basés sur XML peuvent
considérer l'usage de XLink ainsi que l'utilisation du framework XPointer
et du schéma XPointer element() pour définir la syntaxe des identifiants
de fragment.
XLink n'est ni la seule
conception de liaison qui a été proposée pour XML, ni celle
universellement acceptée en tant que bonne conception. Voir également le
point du TAG xlinkScope-23.
Le but d'un espace de noms XML (défini dans [XMLNS]) est de permettre le déploiement de
vocabulaires XML (dans lesquels des noms d'élément et d'attribut sont
définis) dans un environnement global et de réduire le risque de
collisions nommées dans un document donné, lorsque les vocabulaires sont
mélangés. Par exemple, les spécifications MathML et SVG définissent toutes
les deux l'élément set. Étant entendu que des données XML
provenant de différents formats tels que MathML et SVG peuvent être
combinées dans un document simple, il pourrait y avoir une ambiguïté au
sujet de la nature de l'élément set. Les espaces de noms XML
réduisent le risque de collisions des noms en tirant profit des systèmes
existants pour assigner globalement des noms : le système d'URI (voir
également la section sur l'attribution d'URI (§2.2.2)). En utilisant des espaces de
noms XML, chaque nom local d'un vocabulaire XML est couplé à un URI
(appelé l'URI d'espace de noms) afin de distinguer le nom local des autres
noms locaux appartenant à d'autres vocabulaires.
L'utilisation d'URI apporte des avantages supplémentaires.
D'abord, chaque paire d'URI/nom local peut être associée à un autre URI,
construisant les fondations du vocabulaire du web. Ces termes peuvent être
des ressources importantes, il est ainsi approprié de pouvoir leur
associer des URI.
[RDFXML] utilise la concaténation simple de l'URI d'espace
de noms et du nom local pour créer un URI pour le terme identifié.
D'autres correspondances sont susceptibles d'être plus appropriés aux
espaces de noms hiérarchiques ; voir le point du TAG qui s'y rapporte, abstractComponentRefs-37.
Les concepteurs des formats de données basés sur XML, qui
déclarent des espaces de noms, permettent ainsi de réutiliser ces formats
de données et de les combiner dans de nouvelles façons que l'on imagine
pas encore. La non déclaration d'espace de noms rend une telle
réutilisation plus difficile, voire impossible dans certains cas.
Bonne pratique : Adoption des espaces de
noms
Une
spécification qui définit un vocabulaire XML DEVRAIT placer tous les noms
d'élément et les noms globaux d'attribut dans un espace de noms.
Les attributs se situent toujours
dans la portée de l'élément sur lequel ils apparaissent. Un attribut qui
est « global », c'est-à-dire, un attribut qui pourrait clairement
apparaître sur des éléments de plusieurs types, y compris sur des éléments
appartenant à d'autres espaces de noms, devrait être explicitement placé
dans un espace de noms. Des attributs locaux, associés avec un seul type
particulier d'élément, n'ont pas besoin d'être inclus dans un espace de
noms puisque leur signification sera toujours claire grâce au contexte
fourni par cet élément.
L'attribut
type de l'espace de noms des instances de schéma XML du W3C,
"http://www.w3.org/2001/XMLSchema-instance", ([XMLSCHEMA] section 4.3.2) est un exemple d'attribut
global. Il peut être employé par des auteurs de n'importe quel vocabulaire
pour faire une affirmation, dans des instances de données, au sujet du
type de l'élément sur lequel il apparaît. Comme c'est un attribut global,
il doit toujours être qualifié. L'attribut frame dans un
tableau HTML est un exemple d'attribut local. Placer cet attribut dans un
espace de noms n'a aucun intérêt, puisque l'attribut est peu susceptible
d'être utile sur un élément différent d'un tableau HTML.
Les applications se basant sur le traitement
d'une DTD doivent imposer des contraintes supplémentaires à l'utilisation
des espaces de noms. Les DTD effectuent la validation en s'appuyant sur la
forme lexicale des noms d'élément et d'attribut dans le document. Cela
rend les préfixes significatifs au niveau de la syntaxe, d'une façon qui
n'était pas anticipée par [XMLNS].
Scénario
Nadia reçoit des données d'une représentation provenant de
"weather.example.com" dans un format peu familier. Elle en sait
suffisamment au sujet de XML pour identifier à quel espace de noms les
éléments appartiennent. Comme il est identifié par l'URI
"http://weather.example.com/2003/format", elle demande à son navigateur
d'obtenir une représentation de la ressource identifiée. Elle récupère
quelques données utiles qui lui permettent d'en savoir plus au sujet du
format de données. Le navigateur de Nadia est également capable d'exécuter
certaines opérations automatiquement (c'est-à-dire sans surveillance par
une personne) à partir de données qui ont été optimisées pour des agents
logiciels. Par exemple, son navigateur pourrait, au nom de Nadia,
télécharger des agents complémentaires pour traiter et afficher le
format.
Le fait que
l'URI d'espace de noms puisse être employé pour identifier une ressource
d'information qui contient une information utile, exploitable par la
machine et/ou par les personnes, au sujet de termes de l'espace de noms,
est un autre avantage de l'utilisation des URI pour construire des espace
de noms. Ce type de ressource s'appelle un document d'espace de noms.
Quand un propriétaire d'URI d'espace de noms fournit un document d'espace de noms, il fait
autorité pour cet espace de noms.
Il y
a beaucoup de raisons de fournir un document d'espace de noms. Une
personne pourrait vouloir :
- comprendre le but de cet espace de noms,
- apprendre comment se servir du vocabulaire de balise dans l'espace
de noms,
- découvrir qui le contrôle et ses politiques associées,
- demander à l'autorité l'accès aux schémas ou aux informations
complémentaires le concernant, ou
- reporter un bogue ou une situation qui peut être considéré(e)
comme une erreur
Un processeur pourrait vouloir
:
- obtenir un schéma pour la validation,
- obtenir une feuille de style pour la présentation, ou
- obtenir des ontologies pour faire des inférences.
En général, il n'y pas de
meilleure pratique établie pour créer des représentations d'un document
d'espace de noms. Les attentes des applications influenceront les formats
ou les formats de données utilisés. Elles influenceront également la
localisation de l'information appropriée, soit directement dans une
représentation soit dans une référence qu'elle fera.
Bonne pratique : Documents d'espace de
noms
Le
propriétaire d'un nom d'espace de noms XML DEVRAIT rendre disponible des
informations destinées à être lues par des personnes et des informations
optimisées pour les agents logiciels afin de satisfaire les besoins de
ceux qui utiliseront ce vocabulaire d'espace de noms.
Voici quelques exemples de formats de données
pour des documents d'espace de noms : [OWL10], [RDDL], [XMLSCHEMA] et [XHTML11]. Chacun de ces formats répond à différentes
exigences décrites ci-dessus pour satisfaire les besoins d'un agent qui
souhaite obtenir plus d'informations sur l'espace de noms. Notez cependant
certains problèmes relatifs aux identifiants de fragment et à la négociation de contenu
(§3.2.2) si cette dernière est utilisée.
Voir les points du TAG, namespaceDocument-8 (au sujet des caractéristiques
désirées pour les documents d'espace de noms) et abstractComponentRefs-37 (au sujet de l'utilisation des
identifiants de fragment avec des noms d'espace de noms pour identifier
des composants abstraits).
La section 3 du document "Les espaces de noms
dans XML" [XMLNS] fournit une
construction syntaxique, connue sous le nom de QName, pour exprimer de
façon compacte des noms qualifiés dans des documents XML. Un nom qualifié
est une paire se composant d'un URI, qui désigne un espace de noms et d'un
nom local défini dans cet espace de noms. La documentation "Les espaces de
noms dans XML" prévoit l'utilisation de QName comme des noms pour des
éléments et des attributs XML.
D'autres spécifications, en commençant par [XSLT10], ont utilisé l'idée d'employer des
QName dans des contextes différents que les noms d'élément et d'attribut,
par exemple dans les valeurs d'attribut et dans le contenu des éléments.
Cependant, les processeurs XML généraux ne peuvent pas identifier les
QName de façon sûre lorsqu'ils sont utilisés dans des valeurs d'attribut
et dans le contenu des éléments. Par exemple, la syntaxe des QName se
chevauche avec celle des URI. L'expérience a également montré d'autres
limitations concernant les QName, comme la perte des correspondances
d'espace de noms après la canonisation XML.
Contrainte :
QName se
confondant avec un URI
Ne permettez pas l'utilisation de QName et d'URI dans les
valeurs d'attribut ou dans le contenu d'élément lorsqu'il est impossible
de les distinguer.
Pour plus
d'informations, voir les conclusions du TAG "Utiliser
les QName comme identifiants dans le contenu [Using QNames as Identifiers
in Content]".
Les QName
étant compacts, certains concepteurs de spécification ont adopté cette
syntaxe pour identifier des ressources. Cependant même si cette notation
raccourcie est commode, elle a un coût. Il n'y a pas de manière classique
de convertir un QName en un URI ou vice versa. Bien que les QName soient
pratiques, ils ne remplacent pas les URI comme système d'identification du
web. L'utilisation de QName pour identifier des ressources web, sans
fournir de correspondance à des URI, est inconsistante avec l'architecture
du web.
Bonne pratique : Correspondance de QName
Une spécification dans
laquelle les QName servent d'identifiant de ressource DOIT fournir une
correspondance avec des URI.
Voir le paragraphe Les espace de noms XML (§4.5.3) pour quelques exemples de
stratégies de correspondance.
Voir
également les discussions du TAG, rdfmsQnameUriMapping-6 (au sujet de la correspondance des
QName/URI), qnameAsId-18 (au sujet de l'utilisation de QName comme
identifiants dans le contenu XML) et abstractComponentRefs-37 (au sujet de l'utilisation des
identifiants de fragment avec les noms d'espace de noms pour identifier
les composants abstraits).
Considérons le fragment
XML suivant : <section name="foo">. L'élément section
possède-t-il ce que la recommandation XML désigne comme un ID
foo (c'est-à-dire que "foo" ne doit pas apparaître dans le
document XML global plus d'une fois) ? On ne peut pas répondre à cette
question en examinant seulement l'élément et ses attributs. En XML, la
qualité "être un identifiant (ID)" est associée au type d'un attribut, pas
à son nom. Trouver les identifiants dans un document demande un traitement
complémentaire.
- Le traitement du document avec un processeur qui reconnaît les
déclarations de liste d'attributs provenant de la DTD (dans le
sous-ensemble externe ou interne) pourrait indiquer une déclaration
qui identifie l'attribut
name comme étant un ID.
Note : Ce traitement ne fait pas nécessairement
partie de la validation. Un processeur non validant, gérant les DTD,
peut identifier les ID.
- Le traitement du document avec un schéma XML W3C pourrait indiquer
une déclaration d'élément qui identifie l'attribut
name
comme étant un ID de schéma XML.
- En pratique, le traitement du document avec un autre langage de
schéma, comme RELAX NG [RELAXNG],
pourrait également indiquer les attributs déclarés en tant qu'ID,
comme le schéma XML le définit. Beaucoup de spécifications récentes
commencent à traiter le XML au niveau de l'Infoset [INFOSET] et ne spécifient pas de façon normative
comment un Infoset est construit. Pour ces spécifications, tout
processus établissant le type ID dans l'Infoset (et dans l'Infoset de
post validation avec un schéma (Post Schema Validation Infoset ou
PSVI, défini dans [XMLSCHEMA]) peut identifier de façon utile les
attributs de type ID.
- En pratique, les applications peuvent avoir des moyens
indépendants (comme ceux définis dans la section 3.2 de la spécification XPointer [XPTRFR]) de localiser des identifiants
à l'intérieur d'un document.
Pour compliquer un peu plus les
choses, les DTD établissent le type ID dans l'Infoset alors que le schéma
XML W3C produit un PSVI mais ne modifie pas l'Infoset original. Cela
laisse la porte ouverte pour un processeur de ne regarder que dans
l'Infoset et par conséquent de ne pas reconnaître les ID assignés par le
schéma.
Voir les discussions du TAG,
xmlIDSemantics-32, pour des informations de fond
supplémentaires et [XML-ID] pour une
solution en cours de développement.
La RFC 3023 définit les types de média Internet
"application/xml" et "text/xml" et décrit une convention selon laquelle
les formats de données basés sur XML emploient des types de média Internet
avec un suffixe "+xml", comme par exemple "image/svg+xml".
Les types de média "text" posent deux problèmes
: premièrement, pour les données identifiées en tant que "text/*", les
intermédiaires web sont autorisés à les "transcoder", c'est-à-dire,
convertir les caractères dans un autre encodage. Le transcodage peut
rendre l'auto-description fausse ou peut rendre un document mal formé.
Bonne pratique : XML et "text/*"
En général, un fournisseur
de représentation NE DEVRAIT PAS assigner, à des représentations XML, des
types de média Internet commençant par "text/".
Deuxièmement, les représentations dont les types de média
Internet commencent par "text/" sont supposées, à moins que le paramètre
de jeux de caractères (charset) soit indiqué, être encodées
en US-ASCII. Par ailleurs, la syntaxe XML étant conçue pour rendre les
documents auto-descriptifs, l'omission du paramètre charset
est donc une bonne pratique. Mais très souvent, XML n'est pas encodé en
US-ASCII, l'utilisation des types de média Internet "text/" est donc
contradictoire avec cette bonne pratique.
Bonne pratique
: XML et les encodages
de caractères
En général, un fournisseur de représentation NE DEVRAIT
PAS spécifier, dans les en-têtes de protocole, l'encodage de caractères
pour des données XML. En effet, les données se décrivent elles-mêmes.
La section sur les types de représentation et sur la
sémantique des identifiants de fragment (§3.2.1) aborde
l'interprétation des identifiants de fragment. Les concepteurs de
spécification de format de données basé sur XML devraient définir la
sémantique des identifiants de fragment dans ce format. Le framework
XPointer [XPTRFR] fournit un point de
départ interopérable.
Quand le type de
média assigné aux données de représentation est "application/xml", aucune
sémantique n'est définie pour les identifiants de fragment. Les auteurs ne
devraient donc pas s'en servir pour ce type de données. C'est également
vrai si le type de média assigné possède le suffixe "+xml" (défini dans
"Types de média XML" [RFC3023]). La
spécification du format de données ne définit pas la sémantique des
identifiants de fragment. En bref, le simple fait de savoir que le contenu
est du XML ne fournit pas d'informations au sujet de la sémantique des
identifiants de fragment.
De
nombreuses personnes supposent que l'identifiant de fragment
#abc, lorsqu'il se rapporte à des données XML, identifie un
élément du document possédant l'ID "abc". Cependant, aucun support
normatif ne corrobore cette supposition. Une révision de la RFC 3023 est
attendue et devrait résoudre ce point.
Voir les discussions du TAG, fragmentInXML-28.
4.6. Futures directions pour les formats de données
Les formats de données permettent la
création de nouvelles applications autorisant l'utilisation de
l'infrastructure de l'espace de l'information. Le web sémantique en est
une application, construite sur RDF [RDFXML]. Ce document ne discute pas du web sémantique en
détail. En revanche, le TAG compte le développer dans de futurs volumes de
ce document. Voir les discussions du TAG qui y sont relatives dans httpRange-14.
Un certain nombre de principes généraux d'architecture
s'appliquent à chacune des trois bases de l'architecture du web.
L'identification, l'interaction et la représentation sont
des concepts orthogonaux. Cela signifie que les technologies utilisées
pour l'identification, l'interaction et la représentation peuvent évoluer
de façon indépendante. Par exemple :
- Les ressources sont identifiées par des URI. Les URI peuvent être
publiés sans établir de représentation de la ressource ou déterminer
si des représentations sont disponibles.
- Une syntaxe générique d'URI permet à des agents de fonctionner
dans de nombreux cas sans avoir plus de détails sur les schémas
d'URI.
- Dans de nombreux cas, la représentation d'une ressource peut être
changée sans qu'il y ait de conséquence sur les références à la
ressource (par exemple, en utilisant la négociation de contenu).
Quand deux spécifications sont
orthogonales, l'une peut être changée sans impact sur la seconde, même
s'il existe des dépendances à cette autre spécification. Par exemple, bien
que la spécification de HTTP dépende de la spécification des URI, les deux
peuvent évoluer indépendamment. Cette orthogonalité augmente la
flexibilité et la robustesse du Web. Ainsi, il est possible de se référer
à une image par l'intermédiaire d'un URI sans avoir de connaissances sur
le format choisi pour représenter l'image. L'introduction de formats
d'image, tels que PNG et SVG, est facilitée car elle ne perturbe pas les
références existantes aux ressources d'image.
Principe : Orthogonalité
Les abstractions
orthogonales bénéficient des spécifications orthogonales.
L'expérience démontre que les problèmes
surviennent lorsque les concepts orthogonaux sont définis dans une seule
et même spécification. Considérerons, par exemple, les spécifications de
HTML qui incluent la spécification orthogonale x-www-form-urlencoded. Les
développeurs de logiciel (d'applications [CGI] par exemple) pourraient gagner du temps pour trouver
la spécification si elle était publiée séparément puis citée dans les
spécifications de HTTP, des URI et de HTML.
Les problèmes apparaissent également quand les
spécifications essaient de modifier des abstractions orthogonales décrites
ailleurs. Une version historique de la spécification de HTML a ajouté
la valeur "Refresh" à l'attribut http-equiv de
l'élément meta. Elle a été définie comme étant équivalente à
l'en-tête HTTP du même nom. Les auteurs de la spécification HTTP ont
finalement décidé de ne pas fournir cet en-tête. Ainsi les deux
spécifications ont été discordantes l'une avec l'autre. Par la suite, le
groupe de travail HTML du W3C a supprimé la valeur
"Refresh".
Une
spécification devrait clairement indiquer les fonctionnalités qui en
recouvrent d'autres, définies et gérées par d'autres spécifications.
L'information sur le web et les technologies
utilisées pour représenter cette information évoluent dans le temps.
L'extensibilité est la propriété d'une technologie qui favorise
l'évolution sans sacrifier l'interopérabilité. Voici quelques exemples de
technologies réussies permettant le changement tout en réduisant au
minimum la rupture :
- la spécification de manière orthogonale de schémas d'URI,
- l'utilisation d'un ensemble ouvert de types de média Internet dans
le courrier électronique et HTTP pour spécifier l'interprétation des
documents,
- la séparation de la grammaire générique de XML et de l'ensemble
ouvert des espaces de noms XML pour les noms d'élément et
d'attribut,
- modèles d'extensibilité dans les feuilles de style en cascade
(CSS), dans XSLT 1.0 et SOAP,
- les plug-in des agents utilisateur.
Les extensions HTTP obligatoires
[HTTPEXT] sont un exemple de mécanisme
non réussi. La communauté a cherché des mécanismes pour étendre HTTP, mais
apparemment les coûts de la proposition d'extension obligatoire (notamment
en termes de complexité) étaient supérieurs aux avantages qu'elle apportait
et ont ainsi entravé leur adoption.
Nous revenons, plus loin, sur la propriété
d'"extensibilité", portée par les URI, certains formats de données et par
quelques protocoles (par l'incorporation de nouveaux messages).
Sous-ensemble de langage: un langage
est un sous-ensemble (ou "profil") d'un deuxième langage si tout document
valide avec le premier langage est également valide avec le deuxième et
que les interprétations sont identiques.
Langage étendu: Si un langage est
un sous-ensemble d'un autre, le dernier super-ensemble s'appelle un
langage étendu. La différence entre les langages est appelée l'extension.
Clairement, l'extension d'un langage est meilleure, en termes
d'interopérabilité, que la création d'un langage incompatible.
Dans le meilleur des cas, de nombreuses
instances du langage du super-ensemble peuvent être traitées sans risque
et de façon utile, comme s'ils appartenaient au langage du sous-ensemble.
Les langages qui peuvent évoluer de cette façon, en permettant à des
applications de fournir de nouvelles informations lorsque nécessaire tout
en pouvant interopérer avec des applications qui ne comprennent qu'un
sous-ensemble du langage courant, sont dits "extensibles". Les
développeurs de langage peuvent faciliter l'extensibilité en définissant
le comportement par défaut des extensions inconnues (par exemple, celles
qui doivent être ignorées d'une certaine façon ou qui devraient être
considérées comme des erreurs).
Par
exemple, au début du Web, les agents HTML ont suivi la convention
d'ignorer les balises inconnues. Ce choix a laissé une place à
l'innovation (c'est-à-dire aux éléments non standard) et a encouragé le
déploiement du HTML. Cependant, les problèmes d'interopérabilité ont
également surgi. Dans ce type d'environnement, il y a une tension
inévitable entre l'interopérabilité à court terme et le désir
d'extensibilité. L'expérience prouve que les conceptions qui touchent le
bon équilibre entre la possibilité de changement et la préservation de
l'interopérabilité sont plus susceptibles de prospérer et risquent moins
de perturber la communauté Web. Les spécifications orthogonales (§5.1) aident à réduire le
risque de rupture.
Pour aller plus
loin, voir la section sur la gestion
des versions et l'extensibilité (§4.2). Voir également les discussions
du TAG, xmlProfiles-29 ainsi que les dialectes
HTML.
Des erreurs se produisent dans les systèmes
d'information gérés en réseau. Une condition d'erreur peut être
correctement caractérisée (par exemple, des erreurs syntaxiques en XML ou
des erreurs 4xx en HTTP) ou apparaître de manière imprévisible. La correction
d'erreurs signifie qu'un agent répare une condition de sorte que
dans le système, tout se passe comme si l'erreur ne s'était jamais
produite. La retransmission de données, en réponse à une indisponibilité
temporaire du réseau, est un exemple de correction d'erreur. La reprise sur
erreur signifie qu'un agent ne répare pas une condition d'erreur
mais continue son traitement en avertissant du fait qu'une erreur s'est
produite.
Les agents
corrigent fréquemment les erreurs sans que les utilisateurs en
soient conscients, leur épargnant les détails relatifs aux communications
réseau complexes. D'un autre côté, il est important que les agents fassent
de la reprise sur erreur d'une manière évidente pour les
utilisateurs, puisqu'ils agissent en leur nom.
Principe : Reprise sur erreur
Les agents qui font une
reprise sur erreur en faisant un choix sans le consentement de
l'utilisateur n'agissent pas au nom de cet utilisateur.
Un agent ne doit pas obligatoirement interrompre
l'utilisateur (en affichant par exemple une boîte de dialogue de
confirmation) pour obtenir son consentement. L'utilisateur peut indiquer
son consentement par des options de configuration présélectionnées, des
modes ou des choix graphiques sélectionnables, qui lui donnent un rapport
approprié quand l'agent détecte une erreur. Les développeurs d'agent ne
devraient pas ignorer ces questions relatives à l'utilisation lorsqu'ils
conçoivent le comportement de reprise d'erreur.
Pour favoriser l'interopérabilité, les concepteurs de
spécifications devraient identifier des conditions d'erreur prévisibles.
L'expérience a conduit aux observations suivantes au sujet des approches
de traitement d'erreur.
- Les concepteurs de protocole devraient fournir assez
d'informations au sujet d'une condition d'erreur de sorte qu'un agent
puisse la relayer. Par exemple, un code de statut HTTP 404 (non
trouvé) est utile car il permet à des agents utilisateur de présenter
l'information appropriée aux utilisateurs, leur permettant d'entrer en
contact avec le fournisseur de la représentation en cas de
problèmes.
- L'expérience des coûts de développement d'un agent d'utilisateur
pouvant traiter les diverses formes de contenu HTML mal formé a
convaincu les concepteurs des spécifications XML que les agents se
devaient de soulever une erreur face à un contenu mal formé. Les
utilisateurs étant peu susceptibles de tolérer de tels échecs, ce
choix de conception a mis la pression sur chacune des parties, dans le
but de respecter les contraintes XML, pour le bénéfice de tous.
- Un agent qui rencontre un contenu non reconnu peut le manipuler de
plusieurs façons, y compris le considérer comme une erreur. Voir
également la section sur la gestion des versions et l'extensibilité
(§4.2).
- Le comportement face à une erreur, qui est approprié pour une
personne, peut ne pas l'être pour un logiciel. Les personnes sont
capables d'exercer un jugement à l'instar des logiciels. Une réponse
d'erreur informelle peut suffire à une personne mais pas à un
processeur.
Voir les discussions du TAG, contentTypeOverride-24, qui concernent la source des
métadonnées qui font autorité.
Le web suit la tradition d'Internet, en ce sens
que ses interfaces importantes sont définies en termes de protocoles, en
spécifiant la syntaxe, la sémantique et des contraintes ordonnées de
messages échangés. Les protocoles conçus pour être souples face aux
environnements considérablement variables ont favorisé l'accroissement du
web. Ils ont également facilité la communication à travers des frontières
multiples de confiance. Les interfaces de programmation d'application
(API) traditionnelles ne tiennent pas toujours compte
de ces contraintes. Elles ne le devraient pas forcement non plus. Un effet
de la conception basée sur un protocole est que la technologie partagée
entre les différents agents dure souvent plus longtemps que les agents
eux-mêmes.
Il est classique pour des
programmeurs travaillant avec le web d'écrire un code produisant et
analysant ces messages directement. Il est moins commun, mais pas
inconcevable, que les utilisateurs soient exposés directement à ces
messages. Il est souvent souhaitable de permettre l'accès aux utilisateurs
aux détails des formats et des protocoles : les autoriser à "voir la
source" peut ainsi leur faire gagner en expertise dans les fonctionnements
du système sous-jacent.
Ce
document a été édité (authored) par le Groupe d'Architecture Technique
(TAG) du W3C qui inclut les participants suivants : Tim Berners-Lee
(co-Président, W3C), Tim Bray (Antarctica Systems), Dan Connolly (W3C),
Paul Cotton (Microsoft Corporation), Roy Fielding (Day Software), Mario
Jeckle (Daimler Chrysler), Chris Lilley (W3C), Noah Mendelsohn (IBM),
David Orchard (BEA Systems), Norman Walsh (Sun Microsystems) et Stuart
Williams (co-Chair, Hewlett-Packard).
Le TAG apprécie les nombreuses participations sur sa liste
publique de discussions, www-tag@w3.org (archives), qui ont aidées à améliorer ce document.
Enfin, nous remercions David Booth, Erik
Bruchez, Kendall Clark, Karl Dubost, Bob DuCharme, Martin Duerst, Olivier
Fehr, Al Gilman, Tim Goodwin, Elliotte Rusty Harold, Tony Hammond, Sandro
Hawke, Ryan Hayes, Dominique Hazaël-Massieux, Masayasu Ishikawa, David M.
Karr, Graham Klyne, Jacek Kopecky, Ken Laskey, Susan Lesch, Håkon Wium
Lie, Frank Manola, Mark Nottingham, Bijan Parsia, Peter F.
Patel-Schneider, David Pawson, Michael Sperberg-McQueen, Patrick Stickler
et Yuxiao Zhao pour leurs contributions.